Протокол BGP. Маршрутизация по-взрослому.

Оригинал статьи в блоге LinkMeUp
Тема чертовски глобальная, в эти игры уже играют провайдеры.
В рамках этой статьи мы обсудим следующие моменты:
- Непосредственно протокол BGP, принципы его работы и настройку;
- Поднимем линк с провайдером через BGP;
- Вслед за этим настроим резервирование и балансировку линков;
- Также попробуем в резервирование без BGP, посредством IP SLA.
Прежде чем кидаться на амбразуры, давайте ка вспомним теорию. Поговорим о протоколах динамической маршрутизации в целом. Глобально они делятся на две категории по отношению к автономным системам - AS:
> IGP, Internal Gateway Protocol - внутренние нашей автономки.
> EGP, External Gateway Protocol - соответственно, внешние.
Далее обе эти категории делятся по принципу своей работы - DV (Distance Vector) и LS (Link State).
Как вы помните, внутренние мы уже рассматривали в общей статье о динамической маршрутизации. Речь об ISIS/OSPF/RIP/EIGRP. Таким образом, как следует из названия, эти протоколы занимаются распространением маршрутов внутри нашей сети. С этим всё понятно и прозрачно.
Теперь перейдем к EGP. В мире он представлен лишь одним-единственным протоколом - BGP, Border Gateway Protocol. Этот товарищ организует передачу маршрутов уже между целыми сетями (читай, автономными системами, AS).
То есть какой-либо местный провайдер будет слинкован с вышестоящим поставщиком услуг именно посредством протокола BGP.
В общем применяется всё это примерно так:
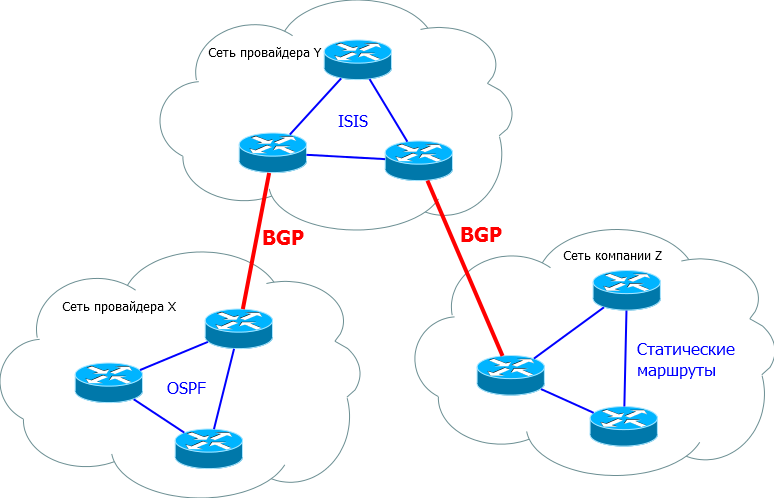
AS. Автономные системы.
Понятия BGP и AS (Autonomous System) очень тесно связаны. Всемогущая википедия говорит нам, что АС - это система IP-сетей и маршрутизаторов под управлением одного или нескольких операторов, имеющих единую политику маршрутизации с интернетом.
Давайте отбросим абстракции и представим живой пример. Пусть город у нас будет единой автономной системой и по аналогии как два города связаны магистралями, также и две АС связаны друг с другом посредством BGP. А внутри городов куча своих дорог, IGP-протоколов.
Картина примерно следующая:
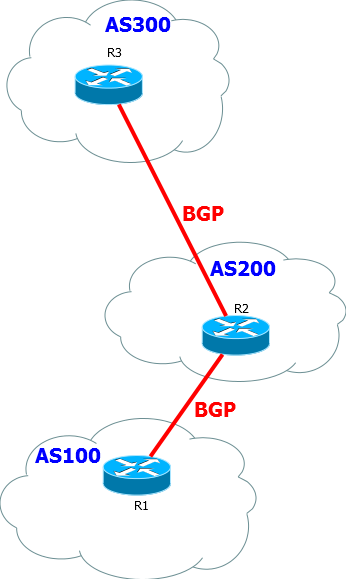
В рамках протокола BGP автономная система это совсем не абстрактная вещь для удобства понимания. Это вещь вполне себе реальная, более того выдачей номеров AS занимаются специальные организации - RIR (Regional Internet Reistry) или LIR (Local Internet Registry). Глобально же всем этим рулит IANA, просто делегирует эту задачу RIR, региональным организациям, таким как RIPE NCC для Европы и стран Ближнего Востока:
А вот статус LIR может получить практически любая организация, и заниматься она будет выдачей номеров AS для относительно мелких контор, такой как в нашем примере. То есть для фирмочки ЛинкМиАп некий провайдер Балаган-Телеком мог бы стать тем самым LIR'ом. У него мы и возьмем AS Number, ASN 64500. У прова же будет номер 64501.
В качестве исторического экскурса укажу такой факт, что до 2007 года использовать можно было только 16-битные номер автономок, т.е. всего 65536 номеров, из которых 0 и 65535 зарезервированы.
Пул 64512-65534 являлся приватным и глобально не маршрутизировался, что-то вроде аналога приватных IP.
Пул 64496-64511 чисто для примеров и разного рода теоретических документаций. Из него мы номера и возьмем.
По состоянию на данный момент можно юзать уже 32-битные номера AS. Что характерно, данный переход куда как легче глобальной миграции с IPv4 на IPv6.
И да, автономки в неком смысле неразрывно связаны с блоками IP-адресов, т.е. в большинстве случаев за каждой AS закреплен какой-то блок IP.
PI и PA адреса
Нет-нет, это отнюдь не неграмотность. PI означает Provider Independent, а не перепутанные буквы IP.
При подключении к прову вам выдается диапазон публичных адресов, которые зовутся PA или Provider Aggregatable. Получить подобный пул не составляет никакого труда, но не будучи LIR'ом, при смене провайдера эти самые PA-адреса нужно будет вернуть. Плюс ко всему допускается подключение только к одному провайдеру, если по факту. Короче говоря, меняете прова и теряете адреса, а новый пров выдаст вам новый диапазон. Но не всё так плохо!
У LIR можно купить блок адресов, который является "провайдеронезависимым" - PI, тот самый Provider Independent и вместе с ним в обязательном порядке ASN. Если брать конкретный случай, то это будет блок 100.0.0.0/23, который мы будем анонсировать посредством BGP своим соседям. Это именно наши IP-адреса, смена провайдера не будет означать их потерю.
И да, получить вожделенный блок PI задача непростая - нужно и документы собрать и подготовить обоснование вашего желание. Подробнее тут.
В мире где мы с вами живем отхватить более-менее крупный блок адресов уже невозможно. RIR уже не выдает новых блоков, разве что LIR еще делает это.
В общем номер AS и в довесок PI-адреса вы получаете в одной и той же организации.
Цитата: Еще запара...
Получив указанное выше богатство нужно отредактировать базу данных RIPE, о чем развернуто можно почитать здесь.
Наш пример подразумевает получение блока 100.0.0.0/23 и AS 64500. Если продолжить сравнение с городом, то мы его наконец-то назвали и получили охапку почтовых индексов.
Полезные статьи:
Инфраструктура сети: AS, PI, LIR etc.
Краткий FAQ на тему.
BGP
BGP служит для передачи информации о наших публичных IP-адресах из своей AS в интернет, т.е. другим AS. И нет никаких исключений. Дата-центры таких гигантов как Google, Яндекс и прочих Майкрософтов подключаются к Интернету отнюдь не благодаря магии, а с помощью всё того же BGP.
Будучи человеком новым в этой сфере, можно подумать: "А на кой черт нужен этот стрёмный BGP, если существует няшный OSPF и вообще можно статических маршрутов накидать?"
Попробуем вкратце это объяснить. Если говорить начистоту, то OSPF при работе между зонами (т.н. area) работает как заправский distance vector протокол. И вообще чисто в теории можно было бы заменить эти самые AS на православные Area и пилить на этой основе глобальную маршрутизацию. Проблема в том, что OSPF просто склеит ласты от гигантских объемов динамически изменяющейся маршрутной информации. Это раз. А два - во взрослых интернетах нельзя просто так взять и выделить некую Area 0.
Что там у нас еще? RIP? EIGRP? Ой нет, спасибо.
IGP - вещь сугубо для внутреннего использования, не нужно, чтобы передаваемая этими протоколами маршрутная информация попадала к нашему аплинковому ISP. Даже если отбросить автономки, клиент очень редко поднимает с провом IGP в чистом виде (разве что при L3VPN). Основная причина в том, что все без исключения IGP лишены возможности максимально гибко работать с маршрутами, те же LS-протоколы хотят знать всё или ничего (окей, можно настроить фильтрацию на границах Area, но это всё костыли).
Что мы имеем? С IGP нам придется вываливать информацию о приватной части сети третьим лицам. Окей, можно городить политики импорта между IGP-процессами, но и это такое себе.
В данный момент глобальная сеть имеет больше 450000 маршрутов. Если даже представить, что уютные OSPF/ISIS могли бы хранить всю эту гигантскую топологию Глобальной Сети, то время расчета алгоритмов SPF затянулось бы на неопределенный срок. А вот и живой пример Яндекса, иллюстрирующий опасность использования IGP вместо глобальных решений.
Именно для этого взаимодействие между AS идет с помощью специального протокола. Какие к нему применяются критерии?
1. Обязательно он должен быть дистанционно-векторным (distance vector). Маршрутизатору не нужно рассчитывать маршрут до каждой сети в интернете. Всё, что ему нужно - выбрать один из предложенных.
2. Требуется гибкая система фильтрации маршрутов. Нужно всегда знать, что следует анонсировать соседям, а что нет.
3. Нужна легкость масштабирования, конечно, защиту от образования петель, а также систему управления приоритетами маршрутов.
4. Высокая стабильность. Это невозможно переоценить. В случае с BGP за качество стыка отвечают как минимум две организации, а значит повышается вероятность потерь/повреждения маршрутной информации при её путешествии во враждебной среде.
5. Система свой-чужой. Протокол должен знать, где его AS, а где чужие.
В горниле этих жестких критериев и родился BGP. Пока рассмотрим основные моменты функционирования этого протокола, а нырнем совсем глубоко позже.
Следует знать, что BGP делится на IBGP и EBGP.
IBGP - передает маршрутную информацию в рамках одной AS. Да, вы не ослышались, BGP умеет и внутри AS, но об этом не сегодня.
EBGP - то, о чем мы и будем говорить, основная среда обитания BGP - между автономными системами.
О нем и пойдет разговор.
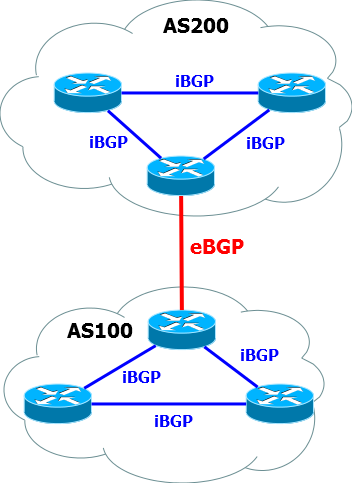
Установление BGP-сессии и процедура обмена маршрутами
Будем оперировать самой стандартной ситуацией, когда мы имеем прямой стык с провайдерским шлюзом.

Железки между которыми поднимается BGP-сессия зовутся BGP-пирами или же BGP-соседями (peer or neighbor)
Протокол BGP не ищет соседей в полностью автоматическом режиме, нужна предварительная настройка.
Разберем процесс установления соседства.
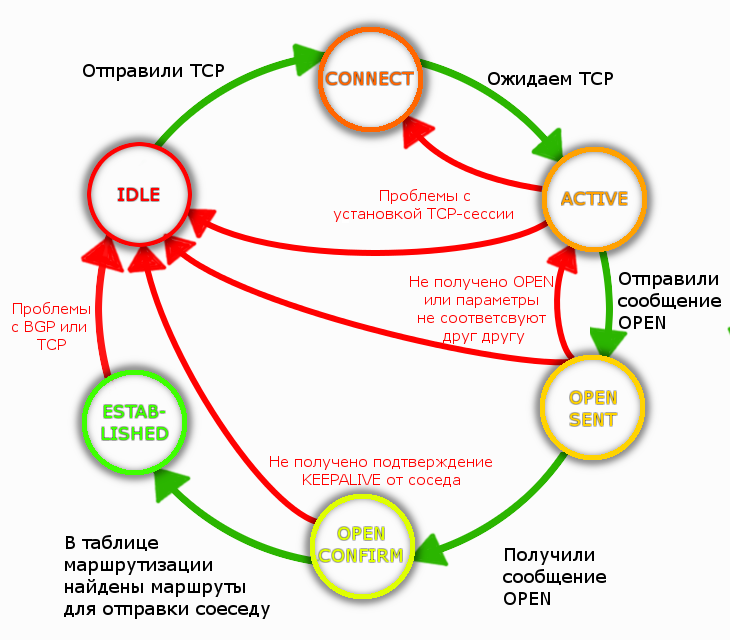
1. Сначала состояние соседства у нас IDLE, тишина.

Состояние IDLE означает отсутствие маршрута к BGP-соседу.
2. Для успешной передачи данных BGP юзает TCP. Так что по факту пиры могут быть соединены не напрямую, а как-то так, например:
Но подключение к провайдеру в большинстве случаев будет прямым, тогда маршрут до соседа всегда будет подключенным непосредственно, т.е. directly connected.
BGP-маршрутизатор (aka BGP-speaker) слушает и шлет пакеты на порт TCP/179. Состояние прослушивания называется CONNECT, длится оно недолго.
После отправки пакета и ожидания ответа от соседа маршрутизатор войдет в состояние ACTIVE.

R1 отправляет TCP SYN на все тот же TCP/179 соседа, тем самым поднимая TCP-сессию.
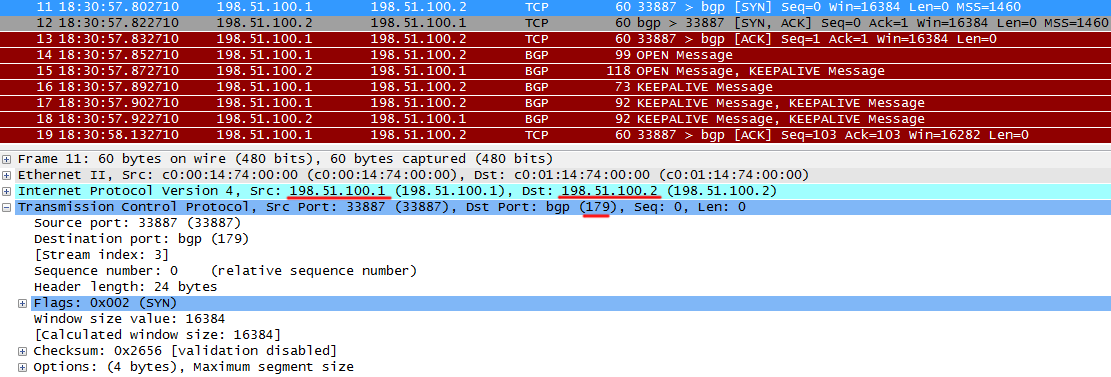
R2 возвращает TCP ACK с подтверждением, а также свой TCP SYN.
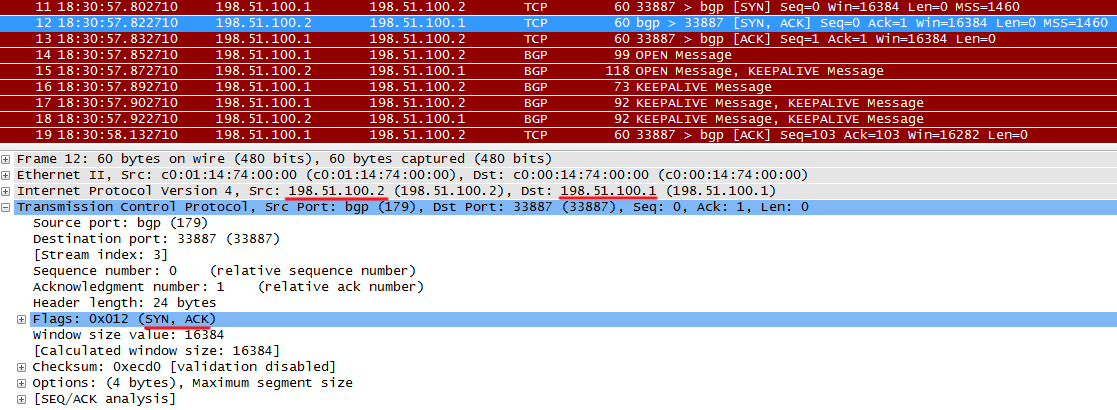
R1 подтверждает получение SYN от R2.
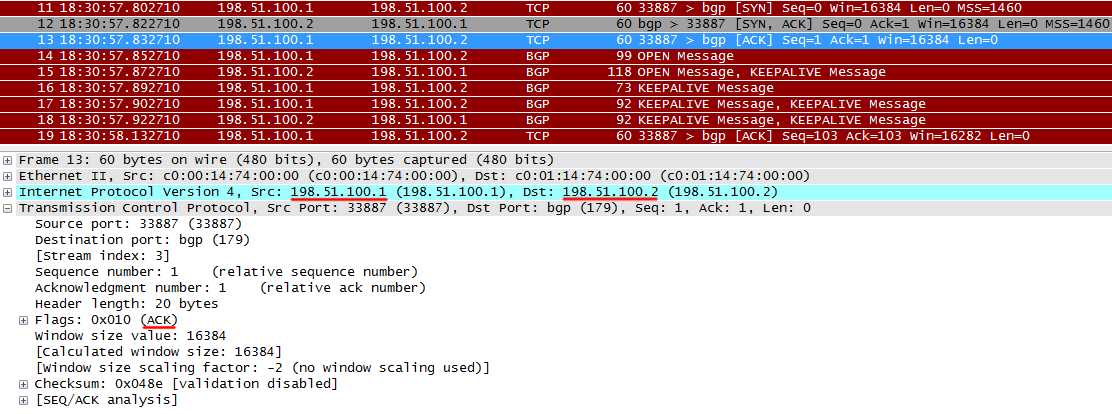
Отлично, TCP-сессия установлена.
В каком случае BGP может зависнуть ACTIVE?
- отсутствует IP-связность с R2;
- не запущен процесс BGP на R2;
- TCP/179 закрыт ACL.
Перед нами пример провала в установлении TCP-сессии. BGP будет останется в состоянии ACTIVE, иногда сваливаясь в IDLE, и снова обратно.
TCP SYN оправлен с R1 на R2:
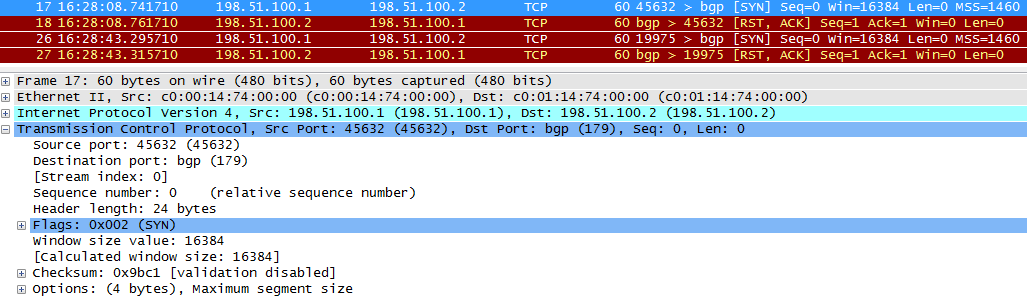
На R2 банально не запущен BGP, и R2 просто возвращает ACK, мол SYN от R1 получен. И вдогонку RST, означающий необходимость сбросить соединение.
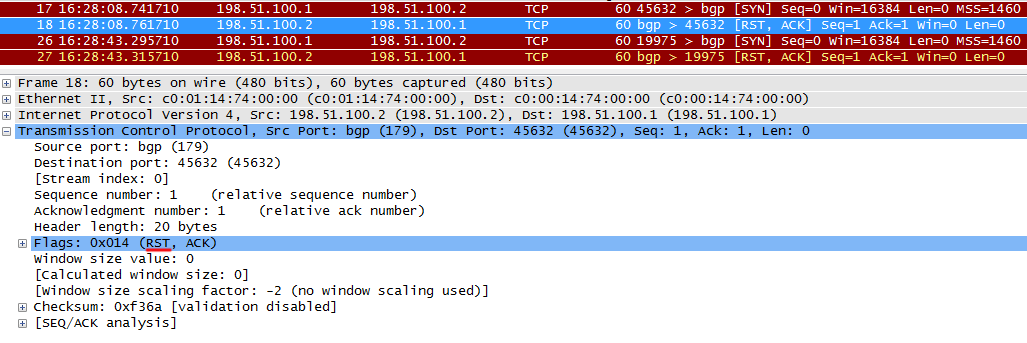
Время от времени R1 будет повторять попытки установления TCP-сессии.
Будьте внимательны! Всегда проверяйте настройки ACL.
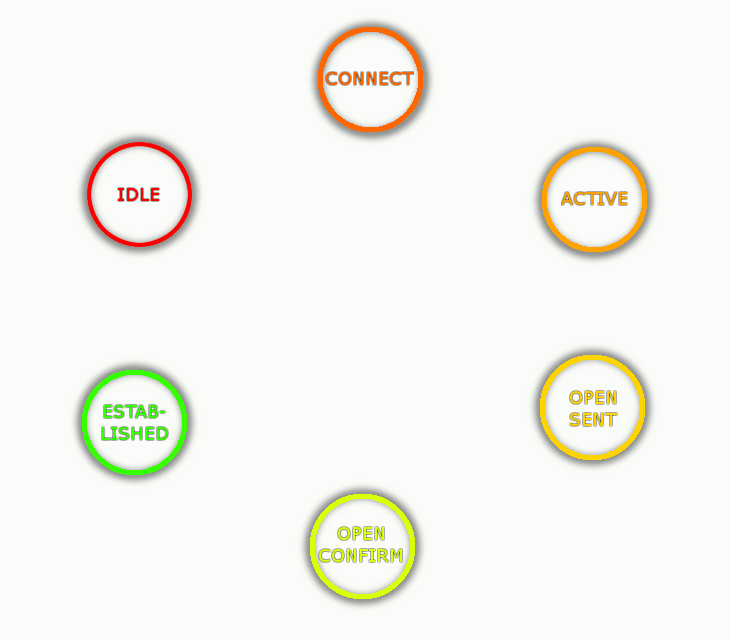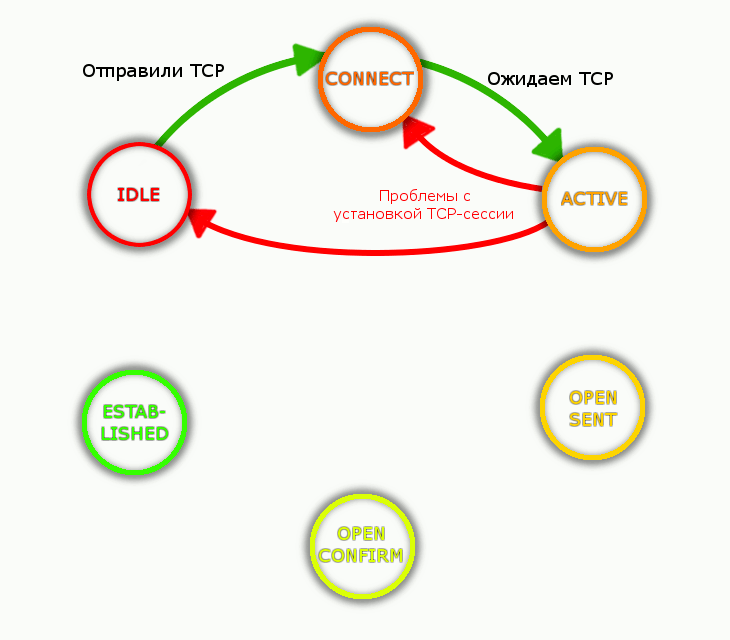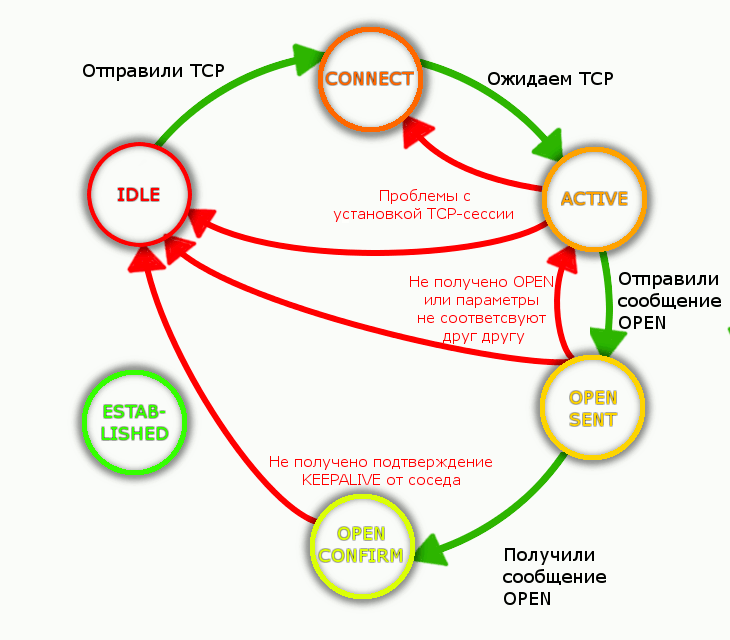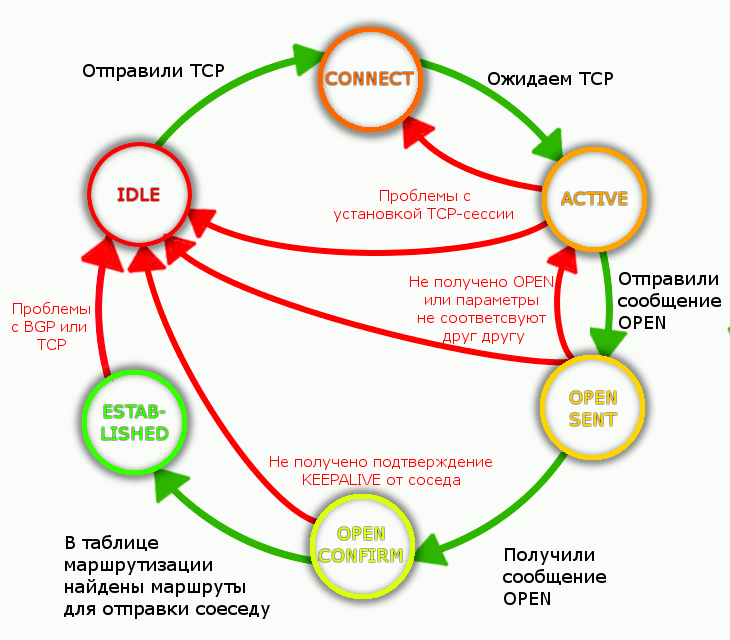
3. После установки TCP-сессии участники BGP начинают обмен пакетами с меткой OPEN.
OPEN - это самый первый тип сообщений в контексте BGP. Они отсылаются первоначально для согласования параметров.
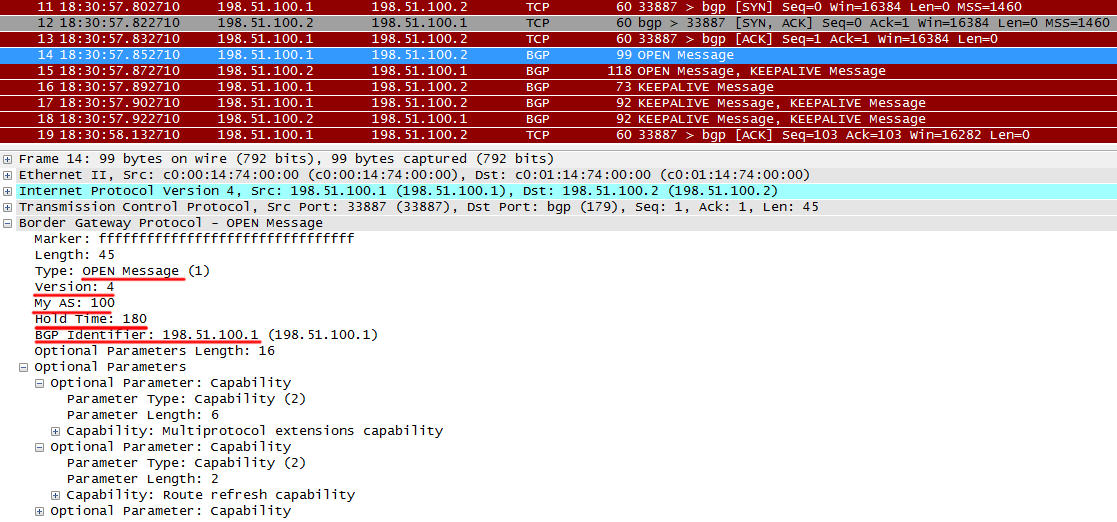
Сообщение несет в себе такие данные как версия протокола, AS Number, Hold Timer, Router ID.
Условия успешной BGP-сессии:
- Одинаковые версии протокола. Несовпадение вряд ли возможно, но все же;
- Конечно, должны совпадать AS Number в OPEN-сообщении и в настройках на удаленной стороне;
- Должны различаться Router ID.
Чуть ниже увидим наличие поддержки дополнительных возможностей протокола.
Итак, R2 получает OPEN от R1, и отправляет ответный OPEN и вдобавок KEEPALIVE, означающий успешное получение OPEN-пакета от R1. Всё это становится отмашкой для R1, и тот переходит в состояние Established.
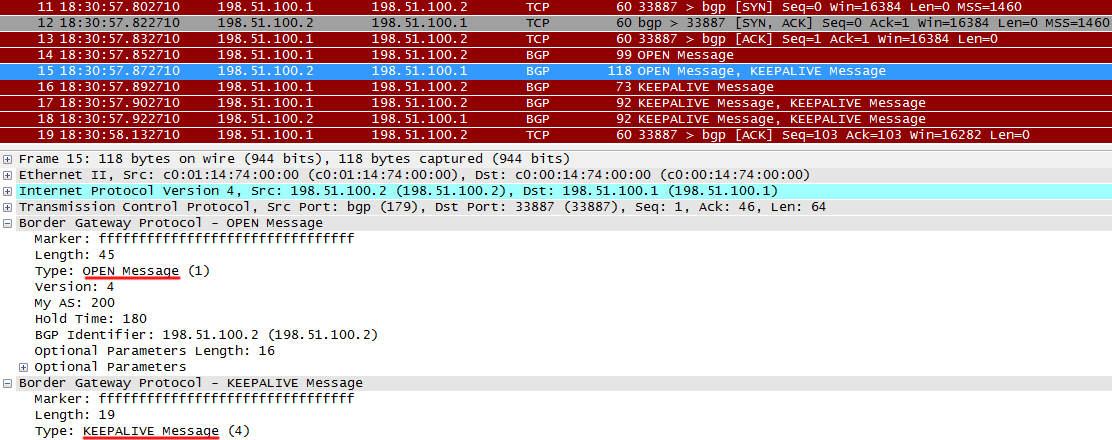
Какие тут могут быть косяки?
а) Неверный AS Number. На R2 у нас настроена AS 300, а вот R1 уверен, что его сосед находится в AS 200.
Вот R2 отправляет OPEN:
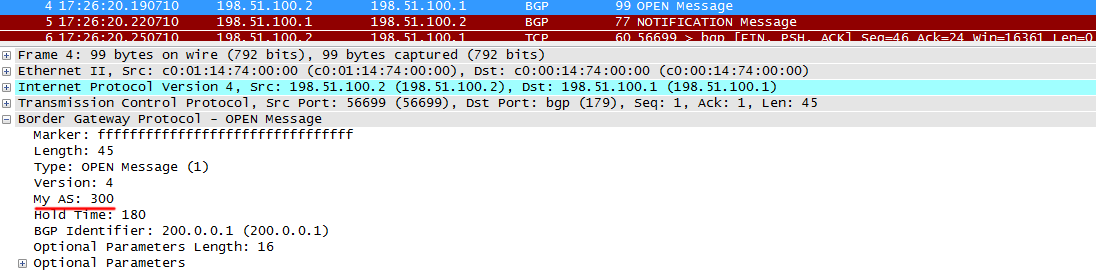
R1 видит, что ASN в сообщении не совпадает с настроенным и дропает сессию с сообщением NOTIFICATION. Данные сообщения отправляются как раз в случае возникновения каких-либо проблем для разрыва сессии.
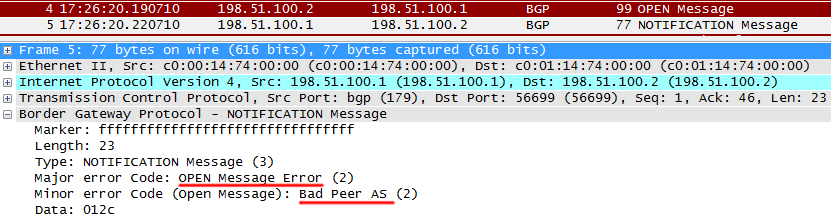
При этом в CLI на R1 можно увидеть это:


б) одинаковый Router ID
R2 отправляет в своем OPEN-сообщении Router ID, совпадающий с этим значением ID у R1.
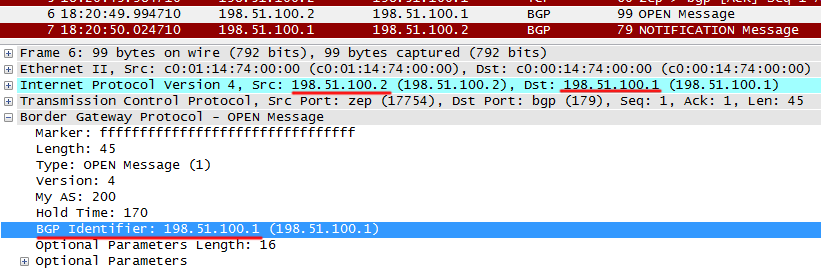
R1 отвечает на это NOTIFICATION-сообщением, дескать что-то тут не так:
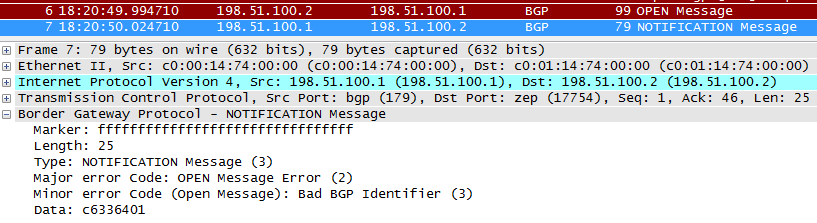
Сообщения в CLI роутера будут примерно такого вида:


После данной ошибки процесс BGP уходит в IDLE, а потом снова в ACTIVE, в попытке снова поднять TCP-сессию и отправить OPEN-сообщение. Мало ли, вдруг ситуация поменялась.
OPEN SENT - состояние по факту отправки OPEN-сообщения.
OPEN CONFIRM - состояние при получении OPEN-сообщения.
Цитата: Замечание
Если в конфигах различается Hold Timer, то будет выбран наименьший из них. А Keepalive Timer при этом будет рассчитан по формуле Hold Timer/3, т.к. его значение в OPEN-сообщении не передается. Это значит, что у пиров может быть разный Keepalive.
Давайте разбираться на кошках. Вот на R2 настроено, что Keepalive 30, а Hold 170:

R2 шлет это в своем OPEN-сообщении. R1 его получает и начинает сравнивать: полученное значение 170, а у самого 180. Понятное дело, будет выбрано то, что меньше - 170, а после считаем Keepalive-таймер:

R2 будет слать свои Keepalive-сообщения каждые 30 секунд, а вот R1 - каждые 56. И ничего, что эти значения разные, главное Hold Timer у роутеров одинаковый и раньше времени сессию никто не дропнет.
Состояния OPENSENT и OPENCONFIRM очень кратковременные, и вы вряд ли успеете их зафиксировать.
4. И вот роутеры входя в состояние стабильное BGP-состояние ESTABLISHED. Значит сконфигурировано всё с обеих сторон верно, дзен достигнут.
У каждого маршрутизатора можно проверить Uptime, сколько процесс BGP пребывает в состоянии ESTABLISHED.

5. Сначала в таблице BGP в самом начале установки сессии имеется информация только о локальных маршрутах:

Пора бы уже начинать обмен маршрутной информацией.
Этим занимаются сообщения типа UPDATE. При этом каждое подобное сообщение несет данные только об одном новом маршруте или же об удалении группы старых. И это может быть одновременно.
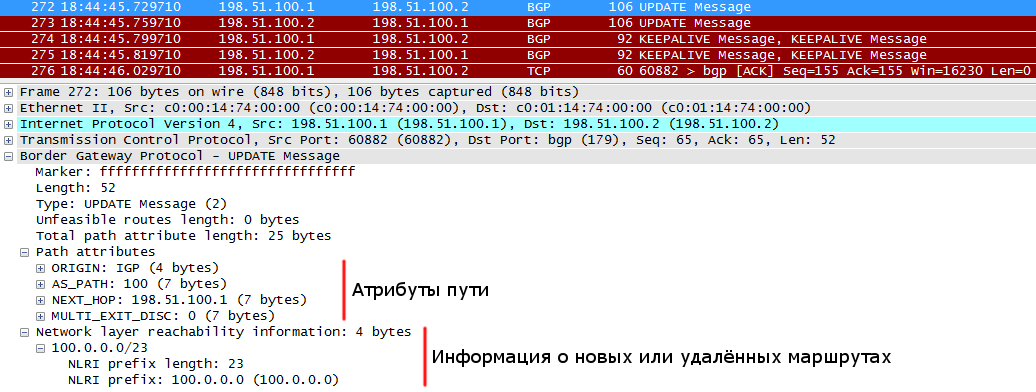
Давайте разбираться. Вот R1 передает для R2 свою маршрутную информацию, как это видно в дампе вайршарка. Path attributes - это атрибуты пути, такие как AS_PATH, который прямо говорит, что это маршрут из AS за номером 100. Далее идет NEXT_HOP, который информирует R2, что ему выставлять в качестве шлюза для этого маршрута. Чисто в теории это может быть и не адрес R1.
А вот атрибут ORIGIN расскажет нам об "истоках" этого маршрута, откуда он взялся.
IGP - прописан статически с помощью команды network или же получен по BGP.
EGP - маршрут получен с помощью одноименного протокола, но его вы уже не увидите, т.к. он вымер как мамонты.
Incomplete - в большинстве случаев означает, что раут пришел через редистрибуцию маршрутов.
Дальше мы видим NLRI – Network Layer Reachability Information, саму информацию о маршрутах. Тут мы и видим искомую сеть 100.0.0.0/23.
Теперь поглядим на UPDATE от R2 к R1.
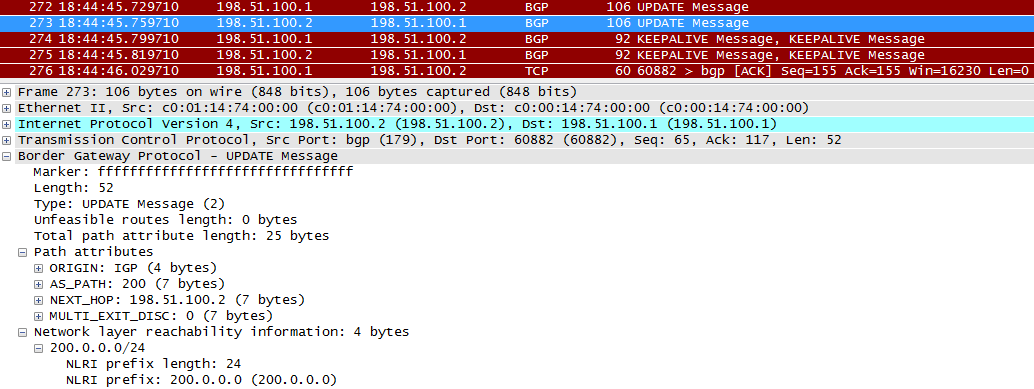
Сообщения KEEPALIVIE подтверждают, что всё ок, информация получена.
Проверим информацию о сетях в таблице BGP:

А также в таблице маршрутизации:

При любых изменениях в сети передаются UPDATE-сообщения на протяжении всей BGP-сессии. И да, вы не увидите здесь синхронизации маршрутной информации как в том же OSPF. Оно и понятно, эти таблички слишком тяжеловесны, по несколько десятков мегабайт, гонять их туда-сюда нецелесообразно.
6. Идиллия наступила, и теперь с настроенной периодичностью маршрутизаторы будут слать KEEPALIVE-сообщения. Тем самым пиры говорят, что у них всё в порядке. По дефолту таймер отправки KEEPALIVE равен 60 секундам.
Цитата: Уточнение
Если с завидной периодичностью BGP-сессия поднимается, а потом также отваливается, то в большинстве случаев это верный признак того, что не проходят keepalive. Порочный цикл обычно имеет величину 60x3=180 секунд или 3 минут (так настроен HOLD-таймер по-умолчанию. Если такое происходит, то искать источник проблемы следует на L2-уровне. Это может быть, например, плохое качество связи, забитый канал, перегрузка на интерфейсе или банальные CRC Errors на нем же.
Процесс BGP шлет еще один тип сообщений - ROUTE REFRESH, эта волшебная просьба запрашивает у соседей заново все маршруты, но при этом не требуется перезапуск всего BGP-процесса.
Подробнее о типах сообщений можно почитать здесь.
Finite-state machine в контексте BGP будет таким:
Тоже, но в виде анимации:
Вот теоретический вопрос. Пусть наша успешная BGP-сессия разменяла 24-часовой аптайм. Каких сообщений точно за это время не было?
Идем дальше.
Представим теперь сеть поинтереснее:
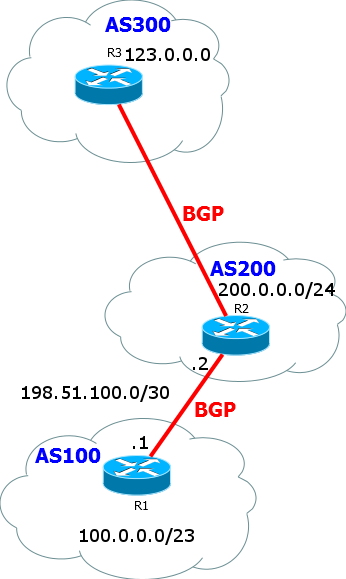
Взглянем на маршрутную таблицу BGP роутера R1:
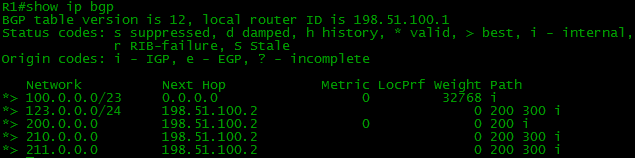
Интересно, тут не просто таблица NextHop'ов или устройств до нужной подсети. Здесь мы видим список AS, он же - AS-Path.
Таким образом для попадания в сетку 123.0.0.0/24 мы должны пройти AS 200 и AS 300.
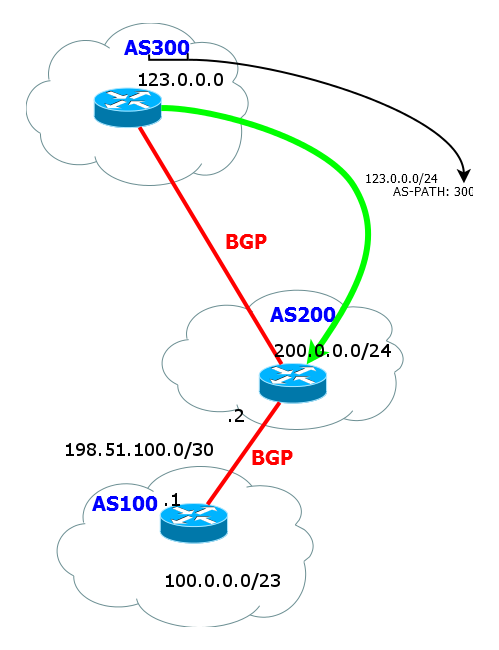
Разберемся с принципом образования AS-path:
1) Пока маршрут находится в пределах AS список пуст, т.к. роутеры прекрасно понимают, что полученный маршрут из этой же AS.
2) Но при анонсе маршрута соседу, BGP-peer'у, он добавляет в список AS-path номер своей AS.
3) При этом на соседской AS список остается прежним, т.е. только с номером изначальной AS.
4) При передаче маршрута от соседской AS дальше в начало списка добавляется номер текущей AS.
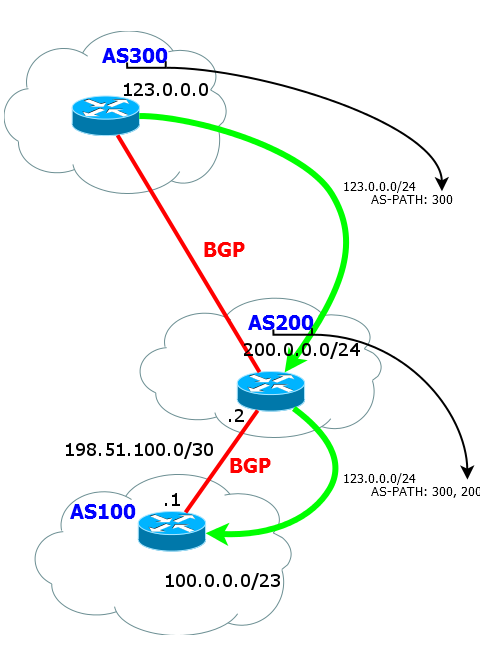
Ну и дальше по такой схеме при дальнейшей передаче маршрута внешнему соседу номер AS всегда будет добавляться в начало списка AS-path, т.е. они стекируются.
AS-path нужен маршрутизатору R1 не просто ради того, чтобы он знал путь до конечной сети, обычного Next-hop'a тут достаточно - маршрутизаторы все равно принимают решение на основе своей таблицы маршрутизации. Причин тут две.
> Избежание маршрутных петель, поэтому в AS-Path номера не должны повторяться.
Ну, точнее как... Они могут и должны повторяться если мы юзаем инструмент AS-Path Prepend или же в случае соединения частей одной AS, которые напрямую друг с другом не связаны.
> Благодаря AS-Path выбирается наилучший маршрут - по дефолту чем AS-Path короче, тем лучше.
Настройка BGP и практика
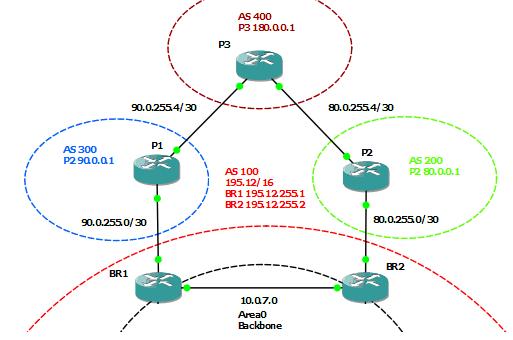
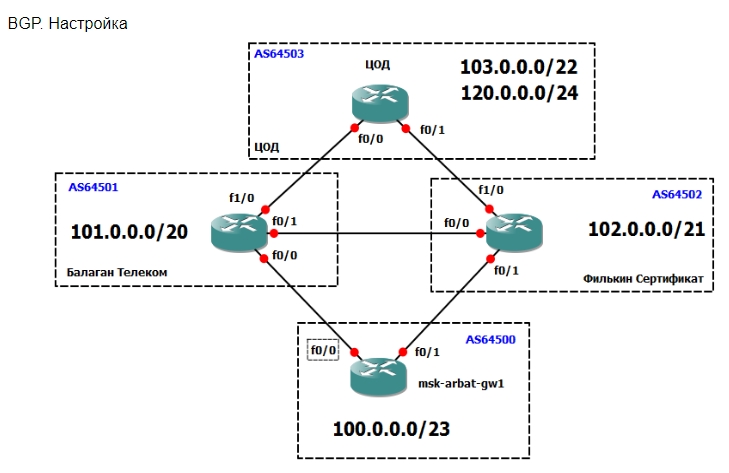
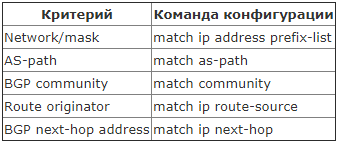
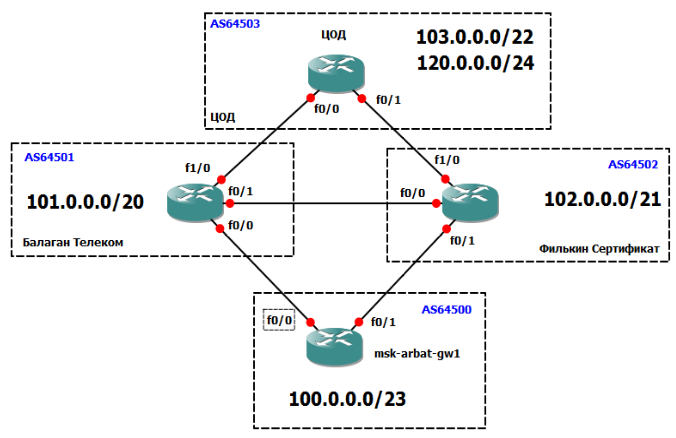
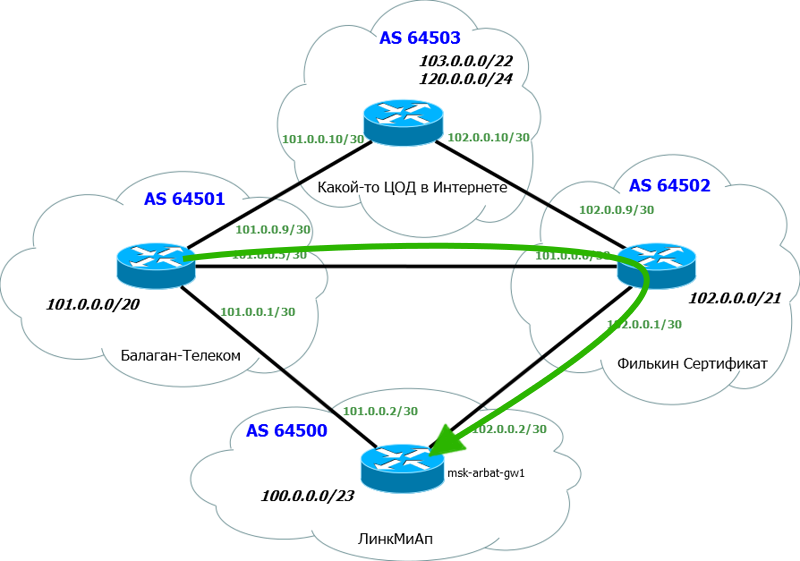
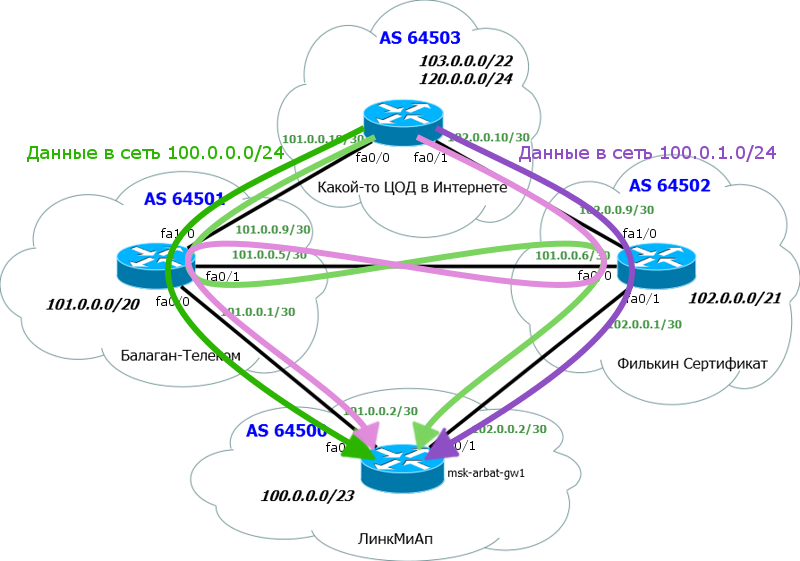
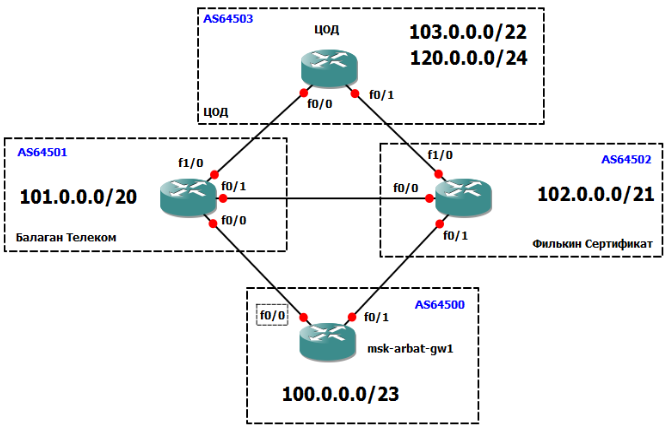
Будем оперировать и теорией и практикой, так будет проще понять происходящее. Снова в качестве подопытного кролика будет использована сеть ЛинкМиАп, при этом оставим на схеме только нужное:
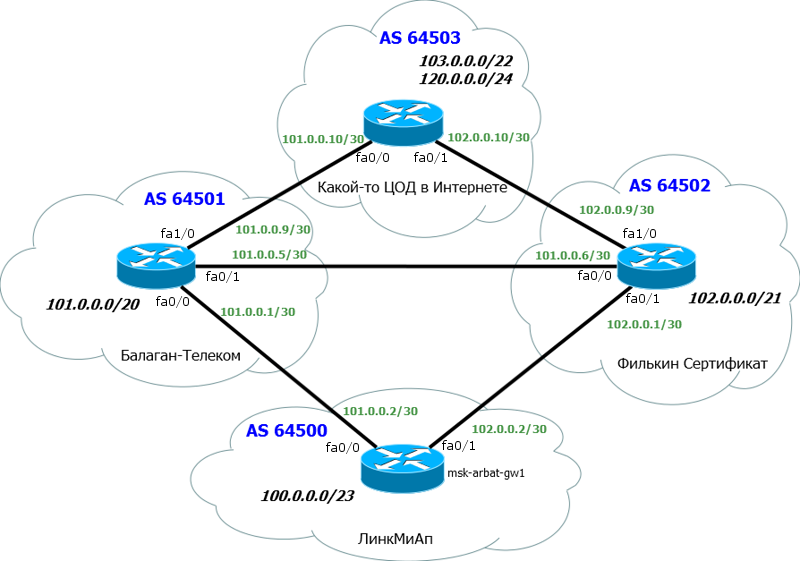
Внизу у нас основной маршрутизатор msk-arbat-gw1. Выпилим пока все старые настройки и будем конфигурировать с чистого листа. Чуть выше видим наших драгоценных ISP - Балаган Телеком и Филькин Сертификат. Каждый пров, конечно, имеет свою AS, наша сеть тоже. Но мы добавим еще одну конечную автономку, некий ЦОД в сети Интернет.
Производить настройку мы будем в идеальных условиях: каждая AS представлена одним-единственным маршрутизатором, не настроено никаких ACL, и всё соединено напрямую без промежуточных устройств.
Нужно поднять BGP-сессию с обоими провайдерами. Давайте разбираться, что нам потребуется для этого.
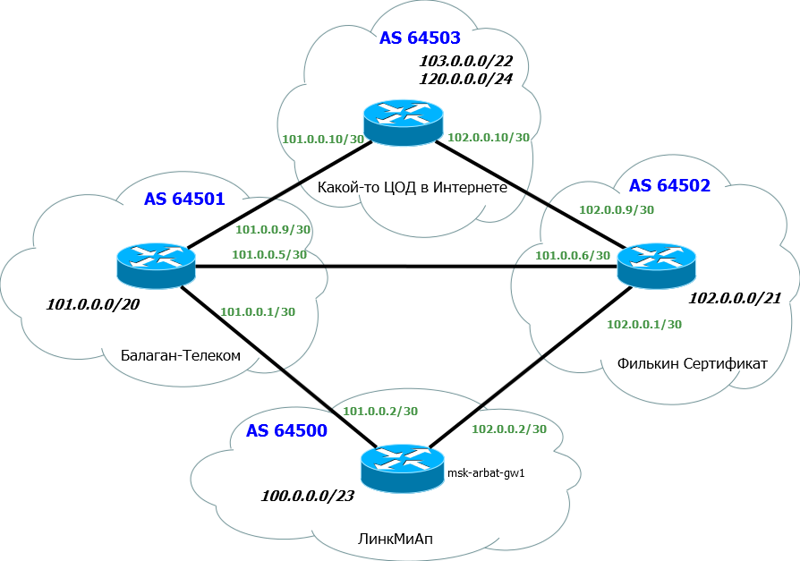
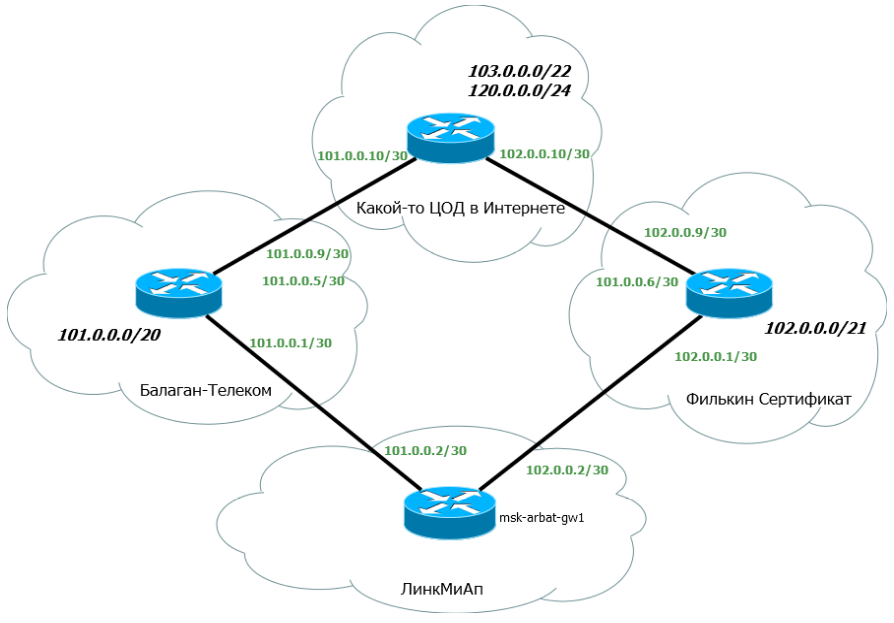
1. Наш AS Number и соответствующий блок IP-адресов. Это AS64500 и блок 100.0.0.0/23;
2. AS Number прова «Балаган Телеком» и его подсеть, с которой мы будем линковаться. AS64501 и линковая подсеть 101.0.0.0/30;
3. То же для провайдера «Филькин Сертификат». AS64502 и линковая подсеть 102.0.0.0/30.
Цитата: Немного матчасти
Вообще-то при подключении по BGP линковыми адресами обычно становятся IP с маской /30, которые выдает вышестоящий провайдер. Зачем это делается? Чтобы трафик шел публичными адресами, без всяких приватных IP посреди трассировки, типа 10.Х.Х.Х какого-нибудь. В этом нет ничего криминального, но всё таки этого правила придерживаются.
Ну-с, приступим? Для начала простое - настройка интерфейсов.
msk-arbat-gw1
R1(config)#int fa0/0
R1(config-if)#ip address 101.0.0.2 255.255.255.252
R1(config-if)#no shutdown
R1(config)#int fa0/1
R1(config-if)#ip address 102.0.0.2 255.255.255.252
R1(config-if)#no shutdown 

Назначим и Loopback-интерфейсу какой-нибудь адрес, чтобы далее проверить связность:
R1(config)#int loopback 0
R1(config-if)#ip address 100.0.0.1 255.255.255.255А теперь самое вкусное - настройка BGP. Будем разбирать каждую строчку.
R1(config)#router bgp 64500Сначала поднимаем процесс BGP и назначаем AS Number, именно тот, что выдал нам LIR!
Далее настраиваем пиринг, задаем информацию о соседе:
R1(config-router)#neighbor 101.0.0.1 remote-as 64501Командой neighbor мы указываем того, с кем будем поднимать сессию. На указанный адрес 101.0.0.1 наш маршрутизатор последовательно отправит сначала TCP-SYN, а затем OPEN-сообщение. Здесь же указываем номер автономки, с которой у нас намечается пиринг - AS64501.
Абсолютно симметричная конфигурация на противоположной стороне:
R2(config)#router bgp 64501
R2(config-router)#neighbor 101.0.0.2 remote-as 64500В CLI появится сообщение:
*Mar 1 00:11:12.203: %BGP-5-ADJCHANGE: neighbor 101.0.0.2 UpУра? Ура, но проверим состояние процесса.
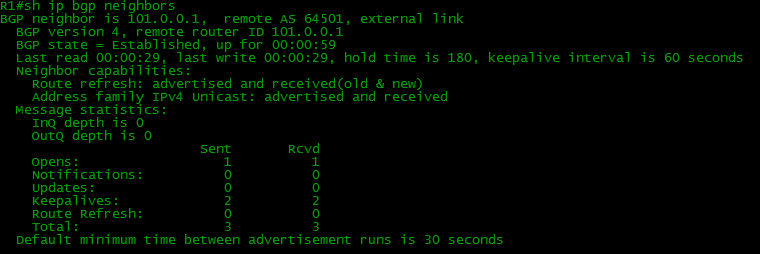
Одно состояние сменяет другое и вот достигнут Established. Маршрутизатор за это время отправил одно OPEN-сообщение и аналогичное получил, а также получил и принял по два KEEPALIVE.
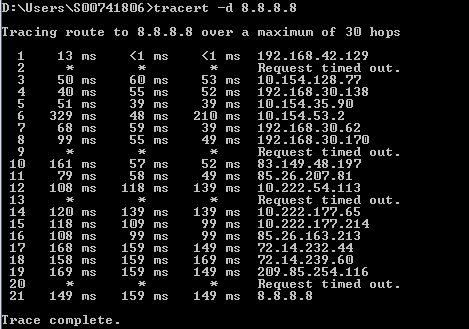
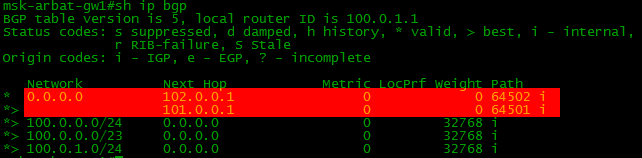
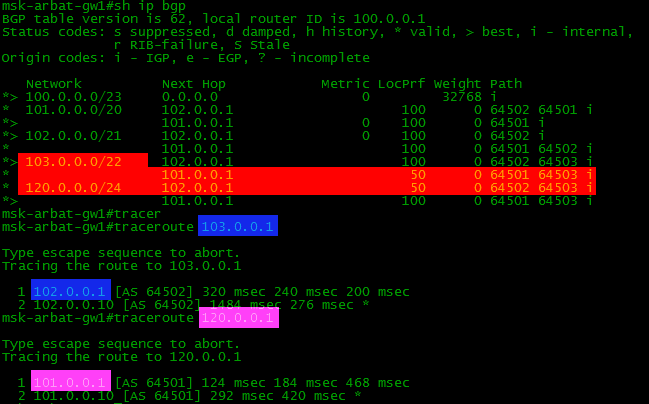
Проверим о каких сетях знает BGP.
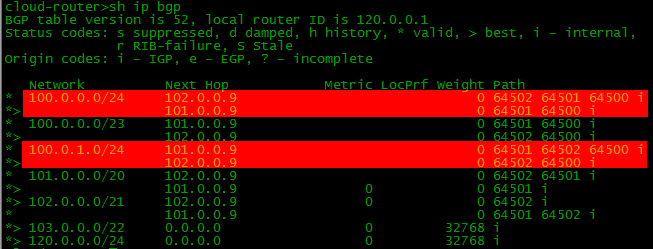
sh ip bgp
Ни-че-го. Смотрим на R2.
И тут тоже самое.
А всё тут просто. До прописанной командой network сети должен быть точный маршрут, в противном случае она не окажется в таблице BGP. А муршрута нет:
А его и вписывать некуда, кроме разве что Loopback-интерфейса. Ну нет нигде этой сети. Исхитримся так:
R1(config)#ip route 100.0.0.0 255.255.254.0 Null 0Маршрут говорит нам, что пакеты идущие в эту сеть будут дропнуты. Но это по плану, так надо. Просто напросто при наличии более конкретных маршрутов (маска больше /23, т.е. /24... /30... /32), то следуя правилу Longest Prefix Match будут выбираться именно они.
Радуемся. В BGP-таблице отобразился локальный маршрут:

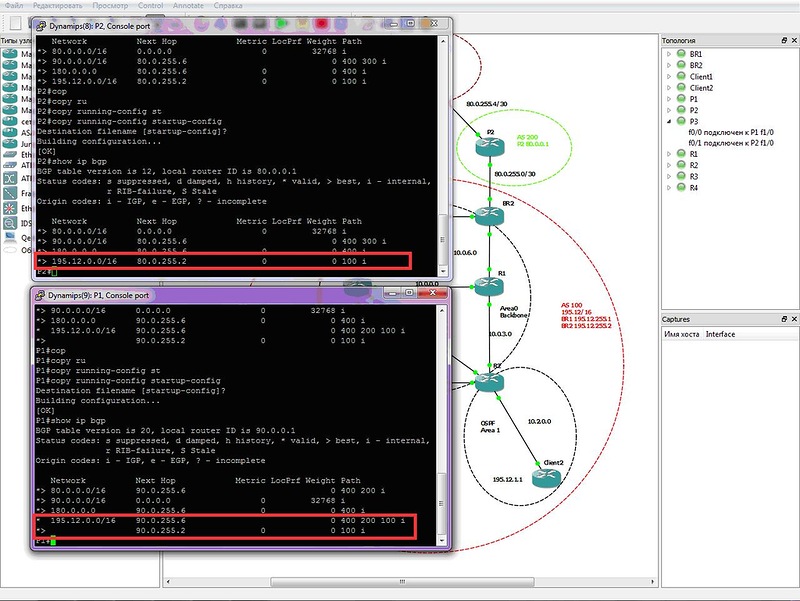
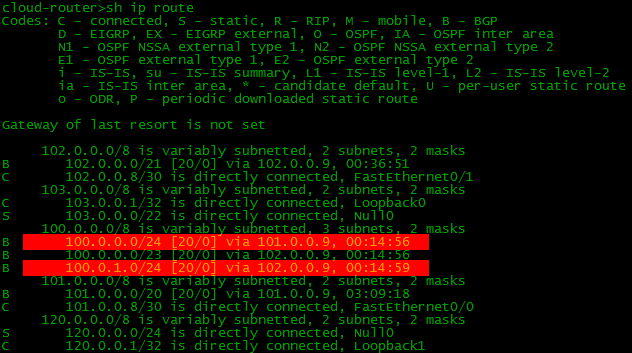
Теперь если мы настроим процесс BGP и нужные маршруты на всех устройствах нашей схемы, то таблички BGP и маршрутизации на бордере (border - пограничный маршрутизатор сети) станет такой:

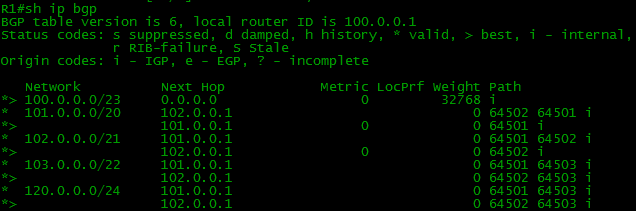
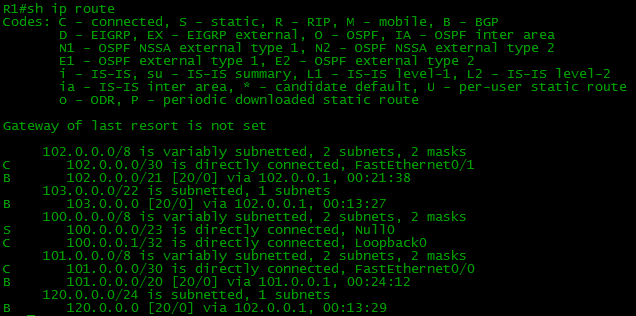
В BGP-таблице, как можно заметить, по два маршрута к некоторым сетям, а вот в таблице маршрутизации он только в одном экземпляре. Просто маршрутизатор выбираем лучший из двух, и именно его закидывает в таблицу маршрутизации.
Ну, вот. Мы настроили BGP в самом первом приближении.

Full View и Default Route
Мимо данной темы в контексте BGP и подключения к прову попросту невозможно пройти. Вот наша уютная компания уже имеет AS Number и вооружилась ворохом PI-адресов. При организации стыка с провайдером Балаган-Телеком нас строго спросят - "будем фулл вью или ограничимся дефолтом?"
Всё, что было у нас выше - это Full View. Маршрутизатор будет изучать все без исключения маршруты Интернета. Наш теоретический случай предусматривает штук пять-шесть маршрутов, но в действительности их более 400000. В итоге нам и один провайдер анонсирует 400 тысяч маршрутов и другой столько же. А вдруг будет еще резервный пров? Получите распишитесь, в итоге больше миллиона маршрутов.
Ну, и чего теперь, отваливать сотни нефти за мощную циску?
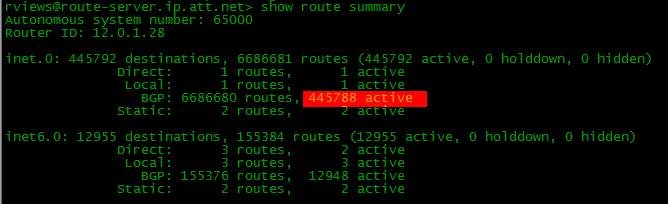
Вот так выглядит саммари маршрутной таблицы route-server.ip.att.net, одного публичного сервера. Можно стучаться телнетом.
По факту не всем автономкам нужно курить Full View, даже более-менее крупным компаниям достаточно Default Route и погнали. Идея простая. Вместо вороха точных маршрутов нам приходит по одному маршруту по-умолчанию от каждого из провайдеров. Впрочем, это может происходить не только вместо, но и вместе.
Разберемся в плюсах и минусах обоих случаев.
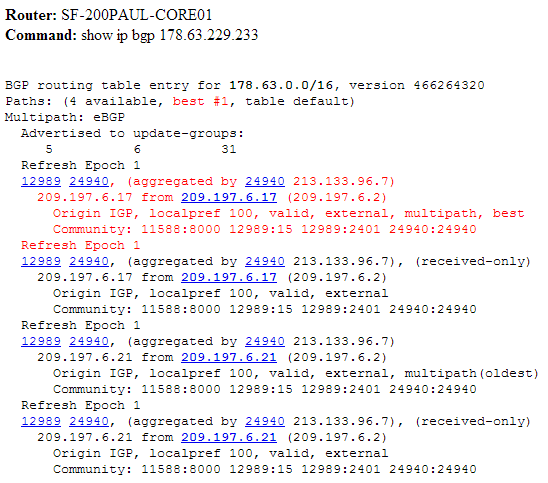
При работе с Full View вся структура интернета у вас перед глазами. Вы можете посмотреть трассу от себя до любого адреса глобальной сети:
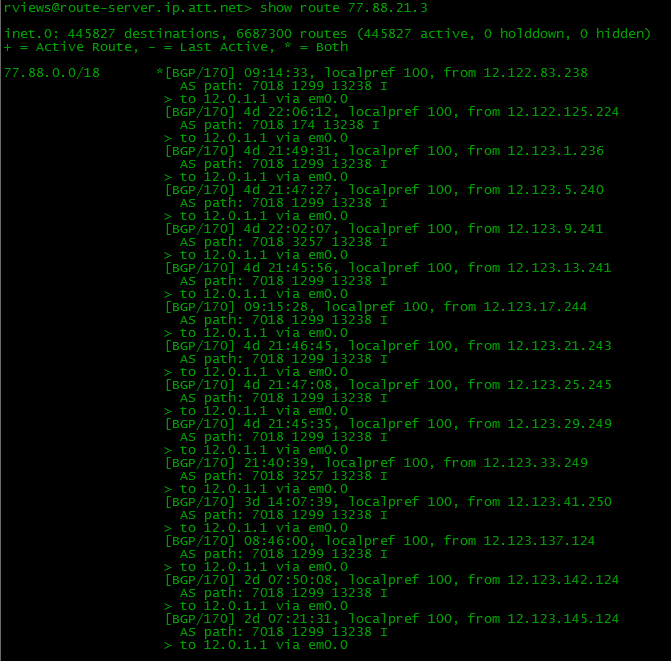
И вы знаете, какие AS ведут к сети назначения, а RIPE позволяет узнать, какие провайдеры обеспечивают передачу. И мы можем без проблем следить за всеми изменениями сети. Даже если где-то далеко на крайних хопах у кого-то что-то отвалится (т.е. не обязательно у вас или одного из ваших провайдеров), BGP обнаружит это и перестроит таблицу маршрутизации в соответствии с изменением топологии, например, пустит трафик через второго провайдера.
И мы вольны гибко рулить маршрутами, тонко настраивая алгоритм выбора наилучшего пути. Допустим, трафик до яндекса мы будем пускать через "Балаган Телеком", а вот уже до гугла - через "Филькин Сертификат". Это будет load balancing - распределение нагрузки.
Сделать это можно, например, путем настройки приоритета маршрутов для определенных префиксов.
Ваш выбор без вариантов Full View, если ваша AS транзитная, т.е. к вам по BGP будут подключены еще клиенты.
Плюсов много, но расплатой здесь будет производительность. Готовьтесь к высокой утилизации оперативки и долгому изучению маршрутной информации после подъема BGP-сессии. Например, даже при кратковременном падении линка до вышестоящего провайдера на полное восстановление уйдет несколько минут.
А теперь Default Route. В первую очередь - это огромная экономия ресурсов нашего оборудования. Обслуживать тоже проще, больше нет задачи гонять тысячи и тысячи маршрутов внутри нашей AS. С другой стороны вы понятия не имеете о состоянии интернетов и доступности конечных узлов - вы тупо шлете трафик на дефолт, прилетевший от провайдера, апстрима (upstream). И если проблема где-то дальше, вы о ней не будете иметь понятия, а как следствие падение части предоставляемых сервисов. В этом месте мы отдаем всё на откуп вышестоящему провайдеру, надеясь, что там BGP быстренько перестроится и снова всё взлетит.
Балансировка и распределение входящего трафика не пострадает, мы этим сможем рулить, а вот управление исходящим накроется.
Давайте резюмировать. Если у вас нет цели гонять через себя транзитный трафик (подключать через себя другие AS) и не требуется гибкое распределение исходящего трафика, то вам дорога к Default Route.
Но вот точно не имеет смысла принимать от одного провайдера анонсы Full View, а от другого Default Route, т.к. один линк всегда будет простаивать и не станет гонять через себя исходящий трафик, ведь выбираться будет более специфический маршрут, который точно найдется среди анонсированного вам Full View.
Но ничего не мешает брать от всех провов Default Route и в нагрузку определенные префиксы (конкретно этого провайдера, например). Тогда до нужных ресурсов у вас будут специфические маршруты, но при этом без Full View.
Взглянем на пример настройки Default Route для линка в нижестоящему маршрутизатору:
balagan-router(config-router)#neighbor 101.0.0.2 default-originateТогда на нашем бордере таблица маршрутов будет такой:
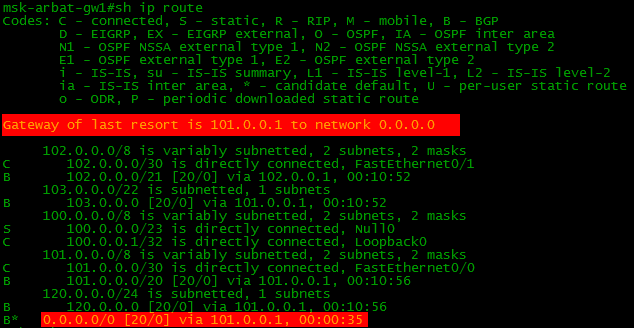
Теперь кроме обычных входящих в Full View маршрутов будет присутствовать и маршрут по-умолчанию.
Цитата: Небольшая ремарка
Default Route - это совсем не противопоставление Full View. Не обязательно жестко выбирать между тем или другим.
Никто не мешает использовать Default Route как дополнение к Full View. Или, например, Default Route и набор специфических маршрутов.
Никто не мешает использовать Default Route как дополнение к Full View. Или, например, Default Route и набор специфических маршрутов.
Интересно почитать: О пользе и вреде полной таблицы BGP
Looking Glass и другие инструменты
Looking Glass - крайне мощный инструмент при работе с BGP. Это некоторое множество серверов в глобальной сети, который позволяют взглянуть на сеть извне. Можно объективно проверить доступность узлов, посмотреть через какие AS трафик идет к нашей автономке, запустить трассировку до нашего блока IP.
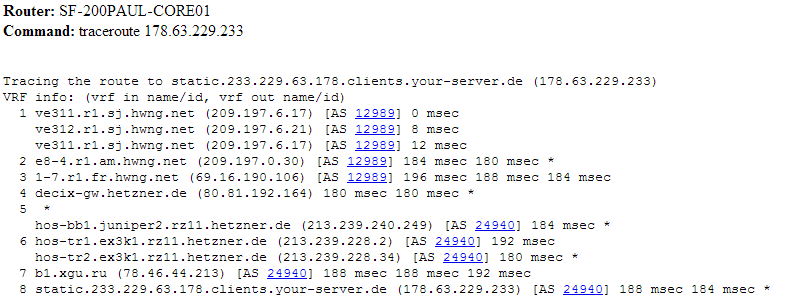
Несколько простых движений, и вот мы уже видим как наши анонсы выглядят извне. Например, вы сможете узнать трассу, по которой к вам возвращаются пакеты. Обратный маршрут может отличаться от первоначального.
Существуют организации, следящие за анонсами BGP в сетях, и в случае аномалий/коллизий уведомляют владельцев этих сетей - BGPMon, Renesys, RouteViews.
Эти организации предотвратили несколько аварий глобального характера.
А, к примеру, сервис BGPlay позволяет визуализировать информацию о распространении маршрутов.
На NAG.ru есть годная статья о глобальных BGP "катастрофах" вроде "AS 7007 Incident" или "Google's May 2005 Outage".
А вот здесь замечательная статья по различным инструментам для работы с BGP.
И еще вдогонку Список Looking Glass серверов.
Control Plane и Data Plane
И еще маленькое отступление перед погружением в пучины маршрутизации. Есть на эту тему годное мозговыносящее чтиво MPLS Enabled Application. Так что там с понятиями в заголовке? Это никакие не уровни сетевой модели, среды или некие моменты передачи данных, а лишь абстрактное деление.
Control Plane - уровень управления, где работают служебные протоколы, которые обеспечивают условия для передачи данных. Вот запускается BGP, следует по всем своим агрегатным состояниям и обменивается маршрутной информацией. Или же когда в MPLS-сетях LDP распределяет метки на префиксы. Таким же макаром обсуждавшийся уже STP обменивается BPDU и строит L2-топологию.
Все эти процессы живут в рамках Control Plane.
А вот Data Plane, передающий уровень - это уже передача полезных данных клиента.
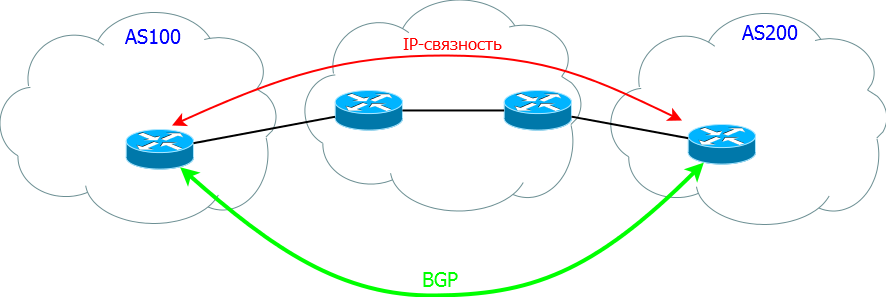
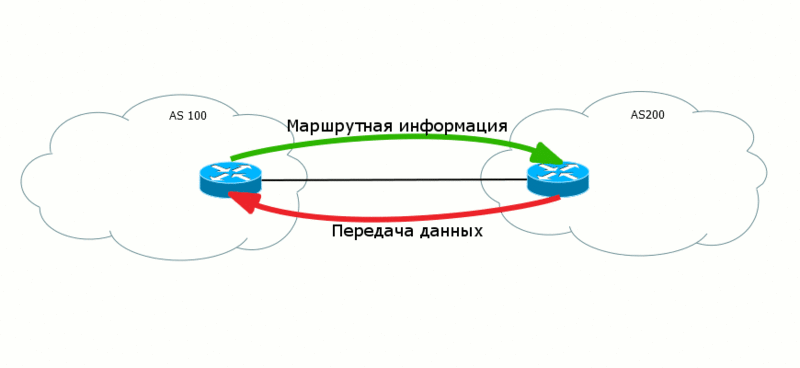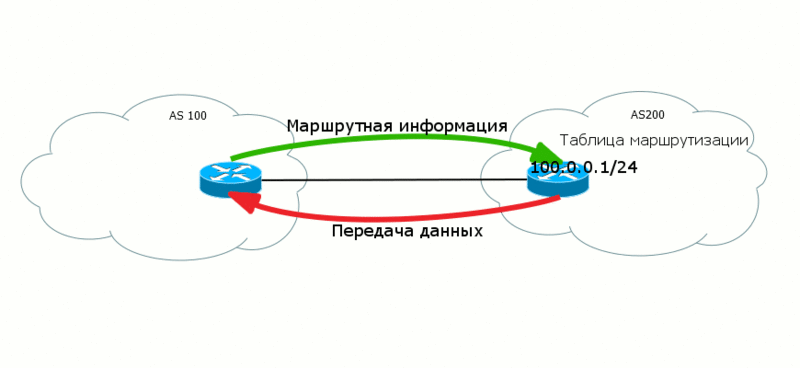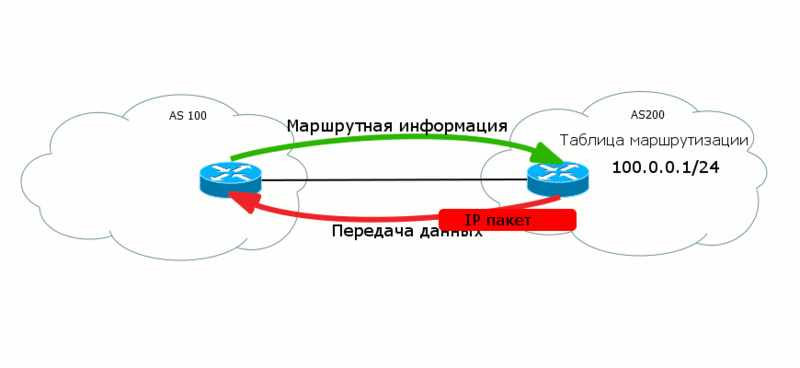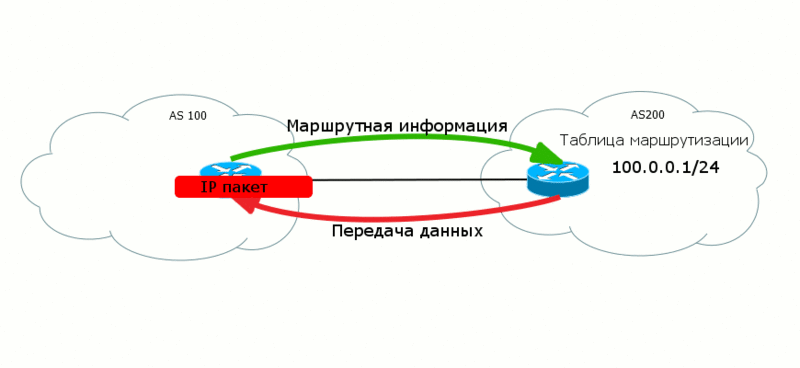
Часто случается, что данные с этих двух уровней ходят в разных направлениях как бы "навстречу друг другу". Таким вот образом маршруты передаются из AS100 в AS200, чтобы в свою очередь AS200 могла передать данные в AS100.
И на разных уровнях могу быть совершенно отличные принципы работы. В том же MPLS на Data Plane создается само соединение, а непосредственно данные передаются посредством заранее определенного пути LSP. Сам же путь определяется по обычному TCP/IP стандарту, т.е. от одного хоста к другому.
Тут нужно понять назначение этих уровней и разницу в них.
Это крайне важный вопрос для BGP. Анонсируя свои маршруты вы одновременно создаете путь для входящего трафика - маршруты исходят от вас, а вот трафик течет к вам.
Выбор маршрута
Что у нас там с маршрутами?
Вот имеется таблица BGP, которая включает в себя все полученные от соседей маршруты:
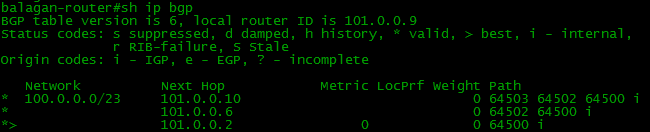
Короче говоря, даже если у нас несколько маршрутов до сети 100.0.0.0/23, то они все окажутся в этой таблице, и неважно какие из них лучше, а какие хуже.
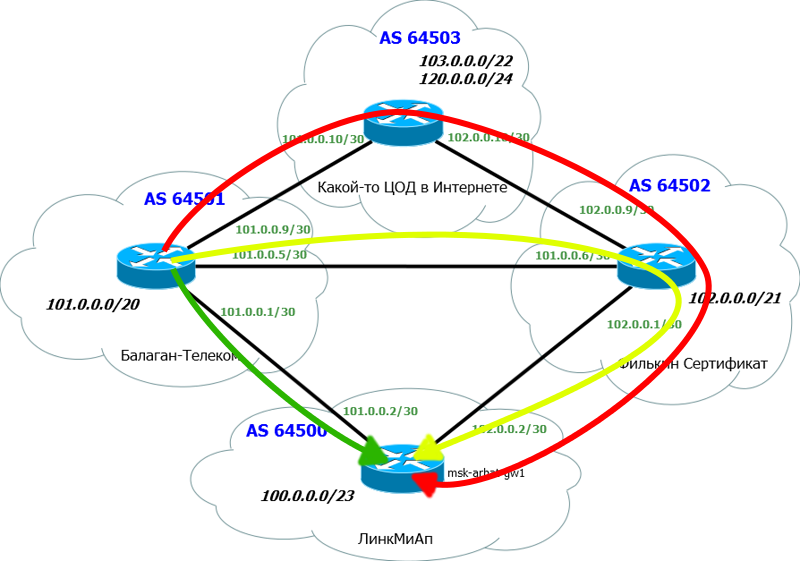
Но также есть и таблица маршрутизации, о которой мы уже столько говорили. И вот уже в ней содержатся только лучшие маршруты. Таким же образом BGP анонсирует своим соседям не все подряд маршруты, а только лучшие. Вы никогда не получите от одного и того же соседа два маршрута в одну сеть.
Какие у нас будут критерии выбора лучших маршрутов? Давайте разбираться.
1. Значение Weight должно быть максимальным (локально для маршрутизатора, актуально для Cisco);
2. Максимальное значение Local Preference (для всей AS);
3. Предпочтения для локального маршрута роутера (т.е. next hop = 0.0.0.0);
4. Самый короткий путь через автономки (смотрим у кого AS_PATH короче);
5. Миниальный Origin Code (IGP < EGP < incomplete);
6. Минимальный MED (передается между автономками);
7. При этом путь eBGP лучше, чем iBGP;
8. Выбор пути через ближайшего IGP-соседа;
При выполнении данного условия, кстати, нагрузка между равнозначными линками будет балансироваться.
А вот эти условия могут у разных вендоров отличаться.
9. Выбор самого старого маршрута для eBGP-пути;
10. Выбор пути через нейбора с самым маленьким BGP router ID;
11. Аналогично, но сосед должен быть с наименьшим IP-адресом.
Сложно? Сложно. Критериев и различных атрибутов много, и опять таки они сложные - сходу тяжело понять. Остановимся чуть позже на принципах выбора маршрутов.

Управление маршрутами
Нас ждет обширная тема - распределение нагрузки при помощи инструментов BGP. Но чтобы это постичь, нам для начала нужно разобраться каким вообще образом мы можем управлять маршрутами в данном протоколе. А возможностей уйма, именно поэтому протокол является таким гибким, прекрасно подходящим для маршрутизации между несколькими провайдерами, в отличие от любого из представителей IGP.
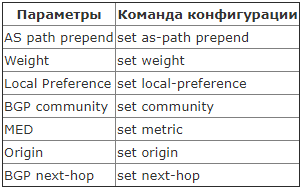
Можно выделить следующие инструменты:
- AS-Path ACL
- Prefix-list
- Weight
- Local Preference
- MED
Много? Но только два первых могут фильтровать анонсируемые и передаваемые маршруты. Остальное - выставление приоритетов.
AS-Path ACL
Механизм этот очень мощный, но не пользуется особой популярностью. При помощи AS-Path ACL вы можете наглухо запретить прием анонсов от AS200, к примеру. Ну, вот не нужны нам от этой автономки анонсы, пускай будем получать их от другой.
Самое сложное - это запомнить все использующиеся при этом подходе выражения:
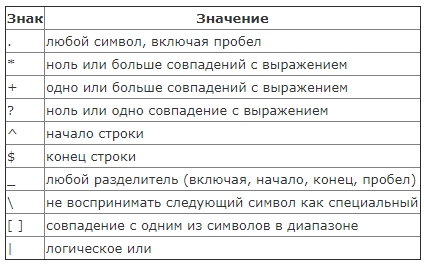
Давайте накидаем примеров, чтобы проще было понять.
_200_ Маршруты проходящие через AS 200
До и после номера AS идут знаки “_”, означающие, что в AS-path номер 200 может стоять в начале, середине или конце, главное, чтобы он был.
^200$ Маршруты из соседней AS 200
“^” означает начало списка, а “$” – конец. То есть в AS-path всего лишь один номер AS – это означает, что маршрут был зарождён в AS 200 и оттуда сразу был передан нам.
_200$ Маршруты отправленные из AS 200
“$” означает конец списка, то есть это самая первая AS, из неё маршрут и зародился, знак “_” говорит о том, что неважно, что находится дальше, хоть ничего, хоть 7 других AS.
^200_ Сети находящиеся за AS 200
Знак “^” означает, что ASN 200 была добавлена последней, то есть маршрут к нам пришёл из AS 200, но это не значит, что родился он в ней же – знак “_” говорит о том, что это может быть конец списка, а может пробел перед следующей AS.
^$ Маршруты локальной AS
Список AS-path пуст, значит маршрут локальный, сгенерированный внутри нашей AS.
Пример
Отфильтруем в нашей сети маршруты, появившиеся в AS64501. То есть мы будем получать от этой автономки все "глобальные интернетовские" маршруты, но ни одного её локального.
ip as-path access-list 100 deny ^64501$
ip as-path access-list 100 permit .*
router bgp 64500
neighbor 101.0.0.1 filter-list 100 in
Инструкция по использованию регулярных выражений
Prefix-list
По сравнению с предыдущим пунктом тут можно сказать всё просто.
Префикс-листы - это уже привычные нам сеть/маска, а мы просто указываем разрешить указанные маршруты или нет.
Синтаксис будет такой:
ip prefix-list {list-name} [seq {value}] {deny|permit}
{network/length} [ge {value}] [le {value}]list-name - собственно название списка. Оказывается обычно в виде name_in или name_out. Это как бы должно намекать нам на какие маршруты (входящие или исходящие) оно будет действовать.
seq - порядковый номер правила, по аналогии с ACL.
deny/permit - этот параметр определяет, запрещающее или разрешающее будет правило.
network/length - определяем сеть и маску, например, 192.168.14.0/24.
Возможны еще два параметра - ge и le. Как и при настройке NAT, это логика "greater or equal" и "less or equal".
То есть можно задать и диапазон, а не конкретный префикс. Будет это, например, так:
ip prefix-list NetDay permit 10.0.0.0/8 ge 10 le 16При это выбраны тогда будут следующие маршруты:
10.0.0.0/10, 10.0.0.0/11, 10.0.0.0/12, 10.0.0.0/13, 10.0.0.0/14, 10.0.0.0/15, 10.0.0.0/16Пример
Давайте запретим принимать анонс сети 120.0.0.0/24 через конкретного провайдера (в нашем случае это будет "Филькин Сертификат"), а прием остальных разрешим. Запись вида 0.0.0.0/0 le 32 будет означать любые подсети с любой длиной маски, которая меньше или равна 32, т.е. 0-32.
ip prefix-list TEST_PL_IN seq 5 deny 120.0.0.0/24
ip prefix-list TEST_PL_IN seq 10 permit 0.0.0.0/0 le 32
router bgp 64500
neighbor 102.0.0.1 prefix-list TEST_PL_IN in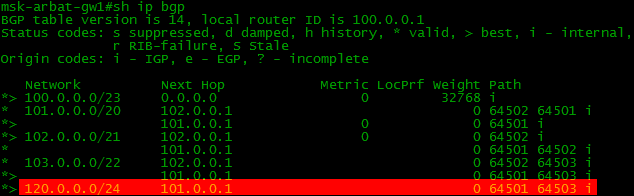
Но здесь нужна небольшая оговорка. Данный пример не означает, что наш BGP-сосед перестанет транслировать нам этот маршрут, еще как будет - он ведь понятия не имеет о настройке наших политик. А вот наш маршрутизатор не будет добавлять полученный анонс в свою таблицу BGP.
Route Map
Правила у нас до этого момента применяли без всяких условий, абсолютно на все анонсы - от пира и к пиру. И вот при помощи этих самых карт маршрутов (прочие вендоры зовут их политиками маршрутизации) мы сможем очень гибко настраивать правила, ловко отсеивая анонсы.
Команда имеет вот такой синтаксис:
route-map {map_name} {permit|deny} {seq}
[match {expression}]
[set {expression}]Что мы тут имеем?
map_name – имя карты, как ни странно;
permit/deny – говорим, что разрешаем или нет прохождение данных, подпадающих под условия нашей route-map;
seq – номер правила в route-map;
match – условие подпадания трафика под данное правило.
expression:
set – выбираем, что сделать с отфильтрованными маршрутами;
expression:
Пример:
Давайте укажем, что в подсеть 120.0.0.0/24 приоритетнее ходить через прова "Балаган Телеком", а вот в 103.0.0.0/22 уже через "Филькин Сертификат". Для этих действий нам потребуется атрибут Local Preference. Выше значение данного параметра - выше приоритет маршрута.
ip prefix-list TEST1_IN seq 5 permit 120.0.0.0/24
ip prefix-list TEST2_IN seq 5 permit 103.0.0.0/22
route-map BGP1_IN permit 10
match ip address prefix-list TEST1_IN
set local-preference 50
route-map BGP1_IN permit 20
set local-preference 100
route-map BGP2_IN permit 10
match ip address prefix-list TEST2_IN
set local-preference 50
route-map BGP2_IN permit 20
set local-preference 100
router bgp 64500
neighbor 101.0.0.1 route-map BGP2_IN in
neighbor 102.0.0.1 route-map BGP1_IN in
Вот мы создали самых обычным образом prefix-list, которым выделяем подсеть 120.0.0.0/24. При этом атрибут permit будет означать, что на данный префикс будут впоследствии применяться политики route-map. Дальше, прямо как в обычных ACL, идет неявное правило deny на всё остальное. В данном конкретном случае оно будет означать, что под действие созданной route-map попадет только 120.0.0.0/24 и больше ничего другого.
В созданной раут-мапе BGP1_IN разрешено прохождение маршрутной инфомации (permit же), попадающий под указанный prefix-list. Об этом говорит данная строчка:
match ip address prefix-list TEST1_INЭтим анонсам мы зададим local preference величиной в 50, взамен стандартных 100:
set local-preferеnce 50Теперь эти анонсы станут менее приоритетными.
Остается привязать карту к определенному BGP-нейбору:
neighbor 102.0.0.1 route-map BGP1_IN inИтог такой:
Прочие примеры мы рассмотрим далее.
Балансировка и распределение нагрузки
На собеседовании вас однозначно спросят, какие вы знаете способы балансировки трафика в BGP.
Уточню. В контексте BGP балансировка и распределение - это два абсолютно разных понятия.
Балансировка нагрузки
Балансировка - это в большинстве случаев распределение нагрузки между несколькими линками трафика, направленного в одну сеть.
Балансировка включается вот так:
Включается она просто
router bgp 100
maximum-paths 2Должны будут выполняться следующие условия:
- Не менее двух маршрутов в таблице BGP для этой сети.
- Оба маршрута идут через одного провайдера
- Параметры Weight, Local Preference, AS-Path, Origin, MED, метрика IGP совпадают.
- Параметр Next Hop должен быть разным для двух маршрутов.
Цитата: Лайфхак
Условие с некст-хопом обходится вот такой командой:
При этом и условие полного совпадения AS-path также умаляется. Но длина всё равно должна быть одинаковой.
router bgp 64500
bgp bestpath as-path multipath-relaxПри этом и условие полного совпадения AS-path также умаляется. Но длина всё равно должна быть одинаковой.
Как всё это проверить на практике? Нужно ведь быть уверенными, что балансировка работает.
Балансировка обычно осуществляется на базе потоков (source address/port, destination address/port) для получения пакетов в правильном порядке. Так что потока нужно создать два. Поехали.
- ping непосредственно с msk-arbat-gw1 на 103.0.0.1;
- подключаемся телнетом на msk-arbat-gw1 (не забыв настроить параметры) с любого другого маршрутизатора и запускаем пинг с указанием источника (чтобы потоки чем-то отличались друг от друга)
После один ICMP-пакет улетит с одного линка, а второй - с другого.
По дефолту пропускная способность внешних каналов никак не учитывается. Но возможность такая есть, и запускается следующим образом:
router bgp 64500
bgp dmzlink-bw
neighbor 101.0.0.1 dmzlink-bw
neighbor 102.0.0.1 dmzlink-bwКонфиг устройств.
Распределение нагрузки
Немного другая история. При распределении происходит несколько более тонкая настройка путей следования входящего и исходящего трафика.
Исходящий
Понятное дело, исходящий трафик будет направляться в соответствии с маршрутами полученными "свыше". Ими нам и нужно управлять. Для начала вспомним принципиальную схему сети:
Для решения наших задач есть несколько способов.
1. Настройка параметра Weight. Это сугубо внутренний цисковский параметр и он никуда не транслируется, т.е. работает исключительно в рамках конкретного маршрутизатора. У прочих вендоров также встречаются аналоги данной установки, тот же PreVal у Huawei, к примеру. Специфического здесь ничего нет, даже зацикливаться на этом не будет. По-умолчанию параметр равен нулю - 0.
Так он применяется ко всем полученным от соседа маршрутам:
neighbor 192.168.1.1 weight 500А таким образом применяем его через route-map:
route-map SET_WEIGHT permit 10
set weight 500
!
router bgp 64500
neighbor 102.0.0.1 route-map SET_WEIGHT in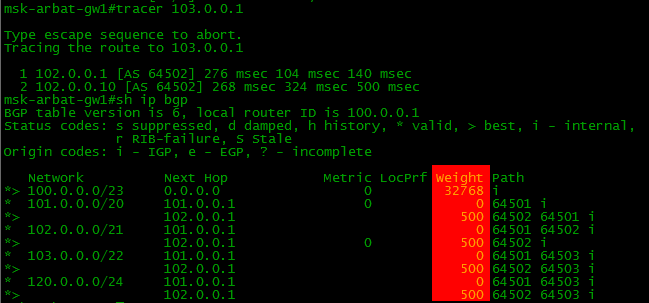
2. Ах да, у нас же есть Local Preference! Параметр стандартный и по дефолту выставлен на 100 для всех маршрутов. Если перед нами стоит задача направлять трафик предназначенный в определенные подсети через определенные линки, то Local Preference - это наш выбор. Да, выше мы уже разбирались с его использованием, поэтому также не будем сильно углубляться.
3. Ну, и балансировка посредством команды maximum-paths.
Входящий
А здесь всё куда сложнее. Даже у очень крупных провайдеров исходящий трафик незначителен в сравнении со входящим. И неровное распределение нагрузки особенно и не замечается. Зато если речь касается Центров Обработки Данных, тех самых ЦОД, или о хостинг провайдерах... То вот здесь уже вопрос балансировки стоит очень остро.
Только в средствах мы стеснены.
1. AS-Path Prepend
Это один из самых часто используемых приемов, искусственное "ухудшение" пути. Случается так, что через одного провайдера ваши маршруты будут переданы с длиной AS-path большей, нежели через другого. Само собой, BGP без вариантов выберет при таких раскладах первого, и трафик будет гонять именно через него. Для того, чтобы выровнять ситуацию добавим лишний "хоп" в AS-Path при анонсировании маршрутов.
А бывает так, что один пров предоставляет нам более широкий канал за меньшие деньги, но путь через него получается длиннее, поэтому трафик уйдет через узкий и более дорогой канал. Дело ясное, что нас такое не устраивает, узкий канал надо сделать резервным.
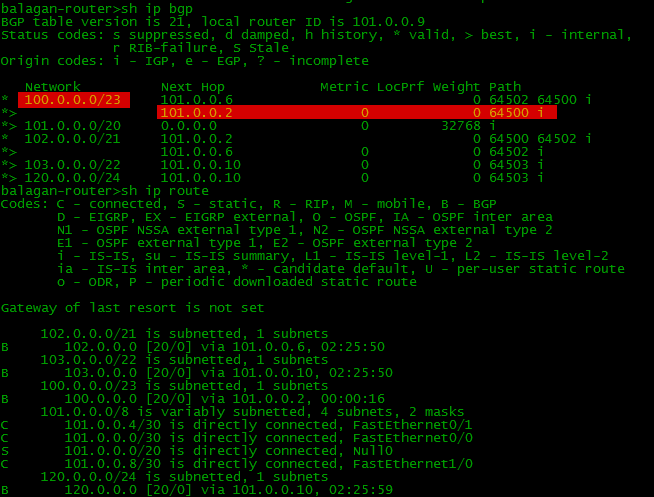
Вот такую ситуацию и разберем. Итак, рассмотрим доступ из сети Балаган Телекома в сеть ЛинкМиАп. Так выглядит таблица BGP и маршрутизации со стороны Балаган Телеком:
Для ухудшения основного пути между ними (прямой линк, между прочим) нам нужно добавить AS в список AS-Path.
router bgp 64500
neighbor 101.0.0.1 route-map AS_PATH_PREP out
route-map AS_PATH_PREP permit 10
set as-path prepend 64500 64500Смотрим результат:
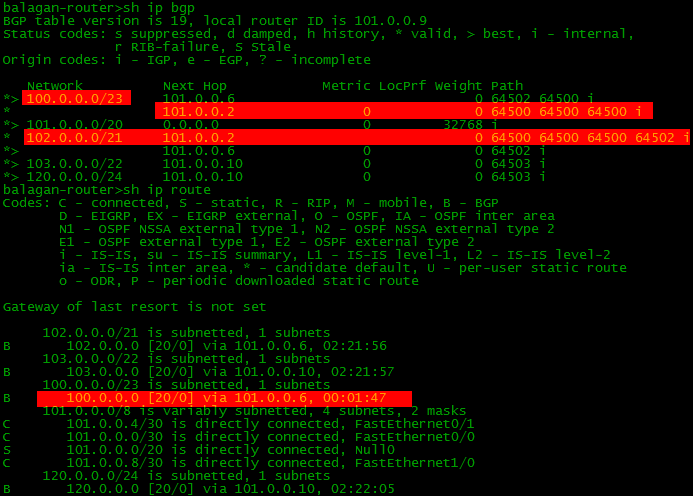
Само собой, будет выбран путь с меньше AS-Path и трафик пойдет через Филькин Сертификат (AS6502).
Этот маршрут добавится в таблицу маршрутизации. И да, обычно в AS-Path добавляют именно свой номер AS. Можно и чужую накинуть, но вас могут не так понять. В итоге мы завернули трафик так как нам надо. Конечно, при падении одного из каналов связи трафик пойдет через резервный, независимо от того каких Prepend’ов вы накидали в AS-Path.
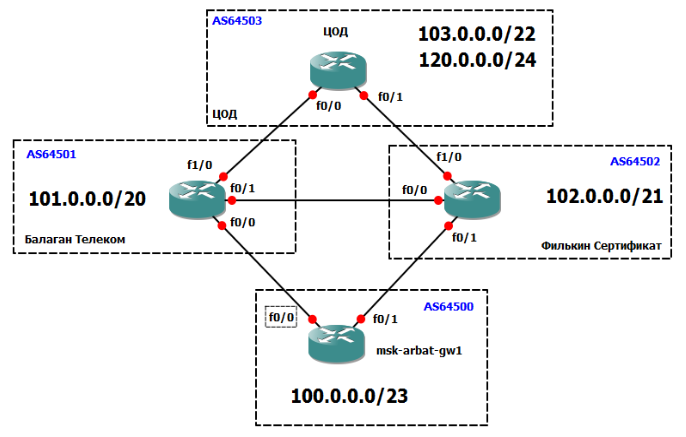
2. MED
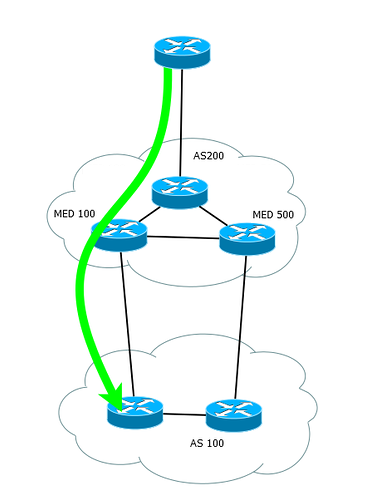
Или же Multiexit Discriminator. Для устройств Cisco он называется метрикой (Inter-AS метрика). MED является довольно слабеньким атрибутом. Почему? Просто его значение проверяется только на шестом шаге при выборе маршрута.
Если параметр Local Preference влияет на выбор пути выхода трафика из Автономной системы, то MED передается BGP-соседям, т.е. другим AS и влияет уже на пути входа трафика.
Новички в BGP часто путают два этих параметра, поэтому давайте разберемся с разницей между ними:

Используется этот параметр редко, поэтому не будем на нем останавливаться. Плюс к тому наша сеть не подходит в качестве примера, т.к. для реализации нужно более одного соединения между AS, а у нас их по одному.
3. Анонс разных префиксов через разных ISP
Это еще один способ распределения нагрузки. Можно раздавать разные сети разным провайдерам. В данный момент для сети ЦОД наши анонсы выглядят так:
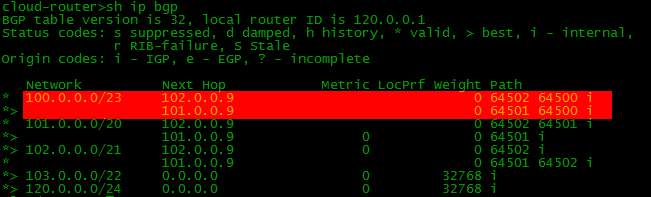
Мы видим, что наша сеть 100.0.0.0/23 известна через два пути, но в таблицу маршрутизации попадет только один. Назад весь трафик тоже пойдет только одним путем - самым лучшим.
Но тут есть нюанс. Мы можем разбить сеть на две подсети /24, отдавая при этом одну в Балаган Телеком, а другую - в Филькин Сертификат. ЦОД при этом будет знать про эти подсети через разные пути:
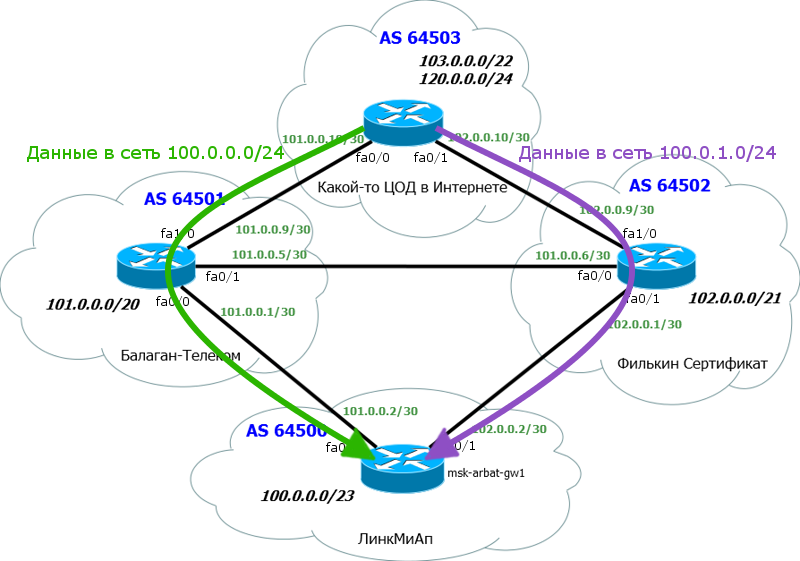
Настраиваться это будет следующим образом:
Первое, что нужно сделать - прописать все подсети, и /23, и обе /24.
router bgp 64500
network 100.0.0.0 mask 255.255.254.0
network 100.0.0.0 mask 255.255.255.0
network 100.0.1.0 mask 255.255.255.0Для успешного их анонсирования нужно создать маршруты до этих подсетей:
ip route 100.0.0.0 255.255.254.0 Null0
ip route 100.0.0.0 255.255.255.0 Null0
ip route 100.0.1.0 255.255.255.0 Null0Дальше нужно создать префикс-листы, каждый из которых будет разрешать только одну подсеть /24 и общую /23.
ip prefix-list LIST_OUT1 seq 5 permit 100.0.0.0/24
ip prefix-list LIST_OUT1 seq 10 permit 100.0.0.0/23
!
ip prefix-list LIST_OUT2 seq 5 permit 100.0.1.0/24
ip prefix-list LIST_OUT2 seq 10 permit 100.0.0.0/23Что теперь? Привяжем нашим нейборам префикс-листы:
router bgp 64500
neighbor 101.0.0.1 remote-as 64501
neighbor 101.0.0.1 prefix-list LIST_OUT1 out
neighbor 102.0.0.1 remote-as 64502
neighbor 102.0.0.1 prefix-list LIST_OUT2 outКак видим, привязывать их нужно на OUT, т.е. на исходящий, потому что данные маршруты будут отправляться вовне, наружу.
Что получилось? Соседу 101.0.0.1 (Балаган Телеком) будут анонсироваться сети 100.0.0.0/24 и 100.0.0.0/23, соседу же 102.0.0.1 (Филькин Сертификат) - сети 100.0.1.0/24 и 100.0.0.0/23.
Получится следующая картина:
Ерунда какая-то получилась? Выходит, что у нас по два маршрута в каждую из сетей /24 - через обоих провайдеров. Но обратимся к AS-Path и схеме для наглядности:
То есть в принципе-то всё правильно, более того, в таблице маршрутизации следующая картина:
Остается только один маленький вопрос. Зачем мы завернули вместе с подсетями /24 и большую сетку /23? Мы же вроде решили, что существует правило Longest prefix match, согласно которому более точные маршруты будут предпочтительнее. То есть этот наш маршрут до /23 при наличии /24 и не нужен вроде бы.
Но постойте.
А если уютная сеточка Балаган Телекома упадет? Что произойдет в этом случае?
Кстати говоря, существуют даже особые организации, которые следят за анонсами BGP в сети и в случае возникновения аварийных ситуаций могут уведомить владельца сети. Бац, и подсеть 100.0.0.0/24 перестает быть известной в сети, т.к. исходя из нашей настройки анонсировалась она только Балаган Телекому. Падает провайдер - падает часть нашей сети. Тут и приходит на помощь более глобальный маршрут 100.0.0.0/23. О нем знает второй пров Филькин Сертификат, и анонсирует его в сеть. Теперь хоть ЦОД и не в курсе про сеть 100.0.0.0/24, но зато 100.0.0.0/23 ему известна, поэтому трафик пойдет через Филькин Сертификат.
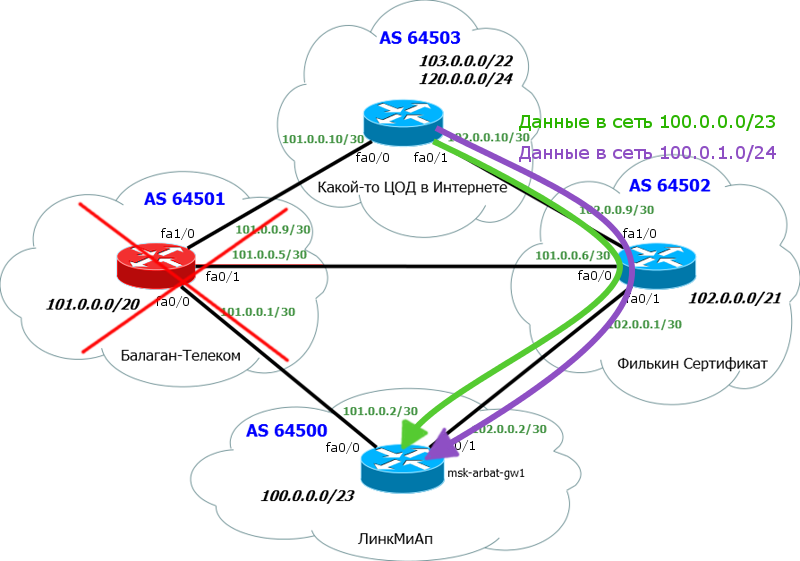
Как видите, мы защищены от подобной нештатной ситуации.
Важно! Помимо непосредственной настройки маршрутизатора надо завести все сетки в базу RIPE - обе /24 и /23.
BGP Community
При помощи BGP Community можно в определенном смысле контролировать провайдера, указывая, что делать с префиксом - кому передавать, кому нет, какой local preference ставить у себя и тому подобное. Сейчас вопрос с коммьюнити поднимать не будем, всё же обширная тема.
Инструкция по видам балансировки и распределения нагрузки
PBR
Всё о чем мы говорили, все технологии статической и динамической маршрутизации описанные здесь и ранее в качестве основного свойства пакета используют destination address, т.е. адрес назначения. Алгоритм их работы прост и в целом одинаков - производится проверка куда идет пакет, искали в таблице маршрутизации самый точный (с наиболее "узкой" маской) маршрут до назначенного адреса (longest match), ну и собственно отправляли пакет на тот интерфейс, который соответствовал выбранному маршруту в route table. Вот и весь принцип маршрутизации. Чёрт, мы уложились в несколько строк, зачем все эти портянки текста? Ладно, не об этом сейчас.
Но вдруг нам такой расклад не нужен? Вот уперлось нам рутить пакеты исходя из адреса источника (source address)! А может нам вообще надо исходить из содержимого пакета, направлять HTTP в одну сторону, а SNMP в другую?
Тут и сваливается на нас аки гром среди ясного неба невиданный ранее зверь - Policy based routing или в переводе с басурманского "маршрутизация на основе политик". Данная технология позволяет рутить трафик, беря во внимание следующие свойства пакета:
- Source address (или же комбинация адреса источника и адреса получателя);
- Информация прикладного уровня модели OSI (application layer);
- Интерфейс на который пришел искомый пакет;
- QoS-метки;
- В целом любая информация из extended-ACL (это и source/destination port, протокол TCP, UDP, etc. и прочее, в самых извращенных сочетаниях). То есть, если мы можем отфильтровать нужный нам трафик расширенными аксесс-листами, то сможем и смаршрутизировать.
PBR дает нам максимальную гибкость при маршрутизации трафика, но всё нужно настраивать вручную, а это зачастую долгий кропотливый труд и сопутствующие этому ошибки. Страдает и производительность, на большей части роутеров PBR куда медленнее обычной маршрутизации. Есть и исключения типа серии Catalyst 6500 с хардварной поддержкой PBR.
Политика для осуществления PBR-роутинга создается командой route map POLICY_NAME и состоит из двух частей:
- Выделение нужного трафика. Может быть сделано либо при помощи ACL, либо исходя из того, на какой интерфейс свалился трафик. Заведует этим команда match в режиме конфигурирования route map.
- Действие, которое будем применено к подходящему под условия трафику. Этим управляет команда set.
Ну, и немного практики.
Вот, к примеру, мы имеем топологию следующего вида:
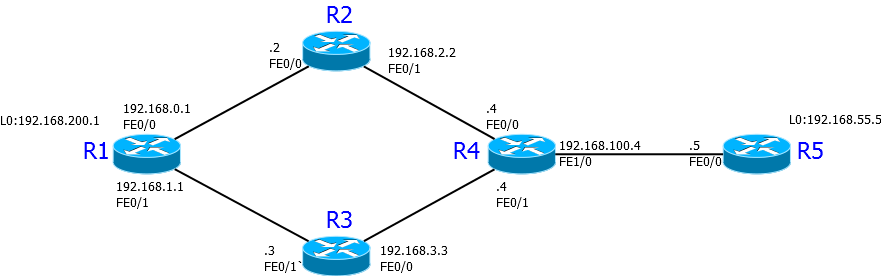
Как видим, на текущий момент трафик от R1 к R5 и обратно идет маршрутом R1-R2-R4-R5. Для удобства схватывания последняя цифра IP-адреса будет и порядковым номером маршрутизатора:
R1#traceroute 192.168.100.5
1 192.168.0.2 20 msec 36 msec 20 msec
2 192.168.2.4 40 msec 44 msec 16 msec
3 192.168.100.5 56 msec * 84 msec
R5#traceroute 192.168.0.1
1 192.168.100.4 56 msec 40 msec 8 msec
2 192.168.2.2 20 msec 24 msec 16 msec
3 192.168.0.1 64 msec * 84 msecДавайте какой-нибудь живой пример. Допустим, нам нужно, чтобы обратный маршрут от R5 (т.е. с его IP в качестве source address) выглядел так: R5-R4-R3-R1. Обратимся к схеме. Очевидно, что решить это должен маршрутизатор R4.
Окей, на этом роутере нам для начала нужно создать ACL, который будет отбирать нужные нам пакеты:
R4(config)#access-list 100 permit ip host 192.168.100.5 anyПосле создаем политику и назовем её как-нибудь очень понятно:
R4(config)#route-map BACKУже находясь в её конфиге указываем интересующий нас трафик:
R4(config-route-map)#match ip address 100И действие, которое будет с ним производиться:
R4(config-route-map)#set ip next-hop 192.168.3.3Теперь зайдем на интерфейс, смотрящий в сторону R5 (PBR работает именно со входящим трафиком) и применим соответствующую политику:
R4(config)#int fa1/0
R4(config-if)#ip policy route-map BACKВремя проверки:
R5#traceroute 192.168.0.1
1 192.168.100.4 40 msec 40 msec 16 msec
2 192.168.3.3 52 msec 52 msec 44 msec
3 192.168.1.1 56 msec * 68 msecВроде бы всё хорошо и всё у нас работает. Но давайте еще раз обратимся к схеме и подумаем, может мы где-то напортачили?
Именно так. Исходя из созданного ACL весь трафик с источником в виде R5 на R3 будет тупо заворачиваться. То есть пакет желающий попасть с R5 на R2 вместо логичного маршрута R5-R4-R2 будет послан далеко и надолго вот туда - R5-R4-R3-R1-R2. Это значит, что ACL для PBR нужно создавать очень вдумчиво и максимально точным образом.
И по поводу применяемого действия. В данном примере мы переопределяем некстхоп для пакетов, но что еще умеет PBR?
- set ip next-hop
- set interface
- set ip default next-hop
- set default interface
Логика первых двух понятна, они соответственно, переопределяют некстхоп и интерфейс из которого уйдет пакет. Само по себе действие set interface чаще всего применимо в прямых линках point-to-point. Если же применить команды set ip default next-hop или set default interface роутер попросту заглянет в таблицу маршрутизации и если найдет там маршрут для проверяемого пакета, то отправит его в соответствии с таблицей. Если маршрута там нет, то только в этом случае пакет уйдет в соответствии с указаниями политики. Снова обратимся к нашему примеру. Если бы в нем мы сказали не set ip next-hop 192.168.3.3, а set ip default next-hop 192.168.3.3, то ровным счетом ничего бы не поменялось, ведь у R4 есть маршрут до R1 через R2. А вот уже в случае отсутствия этого маршрута, трафик бы ушел на R3.
Говоря о команде SET. Она имеет широкое применение, ведь с помощью неё в целевом пакете можно менять много чего от меток QoS/MPLS до атрибутов BGP.
IP SLA
Ну и теперь еще один интересный момент. Давайте вообразим, что трассу R4-R2-R1 у нас поддерживает один провайдер, а вот запасную R4-R3-R1 - другой. И у первого провайдера часто проседает скорость из-за нагрузки, в связи с чем наша телефония (читай, голосовой трафик) начинает заикаться и лагать. А запасной маршрут в этот самый момент времени вполне себе свободен, и было бы неплохо перекинуть трафик на него. Тут как бы всё просто, рисуем route map, выделяющий голосовой трафик и заворачиваем его на нормально работающего провайдера. А потом проходит час пик, и ситуация меняется - трафик снова нужно пускать через первого прова. А если такое происходит по несколько раз в день? Кошмар!
Было бы круто, если можно было в автоматическом режиме считывать характеристики основного канала (ping/jitter, например) и исходя из них рутить трафик либо на него, либо на резерв. И это возможно с помощью IP SLA.
Это технология активного сетевого мониторинга - генерации трафика с целью оценки тех или иных характеристик сети. Но это не только мониторинг, ведь роутер на основе полученных данных может влиять на маршрутизацию, своевременно реагируя и разрешая возникшую проблему. В нашем случае, снимая часть трафика с загруженного канала и перераспределяя его на другой.
Погнали настраивать.
В первую очередь создадим объект мониторинга:
R4(config)#ip sla 1Теперь поглядим, что мы тут можем мониторить:
R4(config-ip-sla)#?
IP SLAs entry configuration commands:
dhcp DHCP Operation
dns DNS Query Operation
exit Exit Operation Configuration
frame-relay Frame-relay Operation
ftp FTP Operation
http HTTP Operation
icmp-echo ICMP Echo Operation
icmp-jitter ICMP Jitter Operation
mpls MPLS Operation
path-echo Path Discovered ICMP Echo Operation
path-jitter Path Discovered ICMP Jitter Operation
slm SLM Operation
tcp-connect TCP Connect Operation
udp-echo UDP Echo Operation
udp-jitter UDP Jitter Operation
voip Voice Over IP OperationКстати, синтаксис команд слегка менялся от версии к версии, так что скажите у себя (config-ip-sla)#? и посмотрите, какие команды маршрутизатор вам предложит. А за подробностями вам сюда.
Самое очевидное рассмотрение принципа работы IP SLA можно провести на примере банального icmp-echo. То есть, если мы пингуем другой конец линии, то трафик по ней пойдет, если нет - то по другой. Но это не так интересно, мы же пойдем немного другим путем, ведь для войс-трафика важным критерием будет jitter, а если совсем конкретно, то udp-jitter.
Начнем.
R4(config-ip-sla)#udp-jitter 192.168.200.1 55555Как видим, сначала указывается вид проверки (udp-jitter в нашем случае), а вот после идет IP-адрес, на который будут отсылаться пробы. Т.е. меряем мы линию от нас до 192.168.200.1, loopback-интерфейса R1. Порт мы берем из головы.
После настраивается частота проверок. По умолчанию она равна 60 секундам:
R4(config-ip-sla-jitter)#frequency 10Далее настроим значение, являющееся предельным, после регистрации которого созданный нами объект ip sla 1 сообщит о проблеме.
R4(config-ip-sla-jitter)#threshold 10Хочется отметить, что некоторые из типов измерений в IP SLA требуют наличия на ответной стороне "ответчика" (responder), а всякие FTP, HTTP, DHCP, DNS - нет. У нас первый случай, udp-jitter требует респондера.
Сконфигурируем R1:
R1(config)#ip sla responderА после запускаем сбор статистики:
R4(config)#ip sla schedule 1 start-time now life foreverСейчас мы запустили объект мониторинга с бесконечным сроком жизни.
Важно! Параметры объекта не поддаются изменению, пока сбор статистики активен. Т.е. для банального изменения параметра frequency нужно сначала вырубить сбор информации - no ip sla schedule 1.
Посмотрим, что у нас там собирается:
R4#sh ip sla statistics 1
Round Trip Time (RTT) for Index 1
Latest RTT: 36 milliseconds
Latest operation start time: *00:39:01.531 UTC Fri Mar 1 2002
Latest operation return code: OK
RTT Values:
Number Of RTT: 10 RTT Min/Avg/Max: 19/36/52 milliseconds
Latency one-way time:
Number of Latency one-way Samples: 0
Source to Destination Latency one way Min/Avg/Max: 0/0/0 milliseconds
Destination to Source Latency one way Min/Avg/Max: 0/0/0 milliseconds
Jitter Time:
Number of SD Jitter Samples: 9
Number of DS Jitter Samples: 9
Source to Destination Jitter Min/Avg/Max: 0/5/20 milliseconds
Destination to Source Jitter Min/Avg/Max: 0/16/28 milliseconds
Packet Loss Values:
Loss Source to Destination: 0 Loss Destination to Source: 0
Out Of Sequence: 0 Tail Drop: 0
Packet Late Arrival: 0 Packet Skipped: 0
Voice Score Values:
Calculated Planning Impairment Factor (ICPIF): 0
Mean Opinion Score (MOS): 0
Number of successes: 12
Number of failures: 0
Operation time to live: ForeverИ наклёпанный нами конфиг:
R4#sh ip sla conf
IP SLAs Infrastructure Engine-II
Entry number: 1
Owner:
Tag:
Type of operation to perform: udp-jitter
Target address/Source address: 192.168.200.1/0.0.0.0
Target port/Source port: 55555/0
Request size (ARR data portion): 32
Operation timeout (milliseconds): 5000
Packet Interval (milliseconds)/Number of packets: 20/10
Type Of Service parameters: 0x0
Verify data: No
Vrf Name:
Control Packets: enabled
Schedule:
Operation frequency (seconds): 10 (not considered if randomly scheduled)
Next Scheduled Start Time: Pending trigger
Group Scheduled: FALSE
Randomly Scheduled: FALSE
Life (seconds): 3600
Entry Ageout (seconds): never
Recurring (Starting Everyday): FALSE
Status of entry (SNMP RowStatus): Active
Threshold (milliseconds): 10
Distribution Statistics:
Number of statistic hours kept: 2
Number of statistic distribution buckets kept: 1
Statistic distribution interval (milliseconds): 4294967295
Enhanced History:Что теперь? Теперь нужно настроить track (сейчас будет неправильный, но верный по смыслу перевод - "отслеживатель"). Исходя из его состояния впоследствии будут происходить изменения в route map. В трек можно заложить задержку между переходами из состояния в состояние, что поможет в случае, если проба с плохими параметрами сражу же сменяется пробой с параметрами хорошими, что при нулевой delayвлекло бы за собой мгновенные изменения маршрутизации.
Нужно указать номер трека и номер объекта ip sla, к которому он привязывается:
R4(config)#track 1 rtr 1Теперь настраиваем задержку:
R4(config-track)#delay up 10 down 15Это будет означать, что если мониторящийся объект отвалился и не выходит на связь в течение 15 секунд, то track сменяет состояние на down. А если объект пребывал в состоянии down, но вдруг поднялся и оставался в этом состоянии более 10 секунд, то track перейдет в состояние up.
Что нужно сделать еще? Естественно, привязать созданный трек к роут-мапе. Еще раз - дефолтный маршрут от R5 к R1 лежит через R2, но у нас в запасниках имеется route map BACK, которая вступит в силу, если источник R5:
R4#sh run | sec route-map
ip policy route-map BACK
route-map BACK permit 10
match ip address 100
set ip next-hop 192.168.3.3Допустим, мы привяжем наш мониторинг к этой карте маршрутов, при этом поменяв строку set ip next-hop 192.168.3.3 на set ip next-hop verify-availability 192.168.3.3 10 track 1, тогда при падении трека эффект будет противоположный (критерием для этого будет падение jitter в sla 1) карта обрабатываться не будет и всё будет происходить согласно route table. А если всё в порядке и трек будет up, то карта будет применяться и трафик пойдет через R3.
Почему так? Маршрутизатор видит, что пакет подпадает под условия match, но set делает не сразу (см. пример с PBR), а сначала проверяет каково состояние track 1, и если тот поднят, то делает set, а если нет, то переходит к следующей строке route map.

