Настройка оборудования Cisco. Протокол STP.
Ранее мы поднимали вопросы коммутации и статической маршрутизации, то есть первичной настройки. Теперь сделаем небольшую передышку и поговорим о стабильности нашей сети.
Стандартная ситуация, вдруг пропала связь до какого-нибудь почтового сервера, не дошли несколько важных писем, а вам прилетел нагоняй. Оказалось, выпал патчик из коммутатора в серверной... Ну, так обычно все и бывает - от того, что в кузнице не было гвоздя.
В этот раз поднимем следующие вопросы:
• проблему широковещательного шторма;
• работу и настройку протокола STP и его модификаций (RSTP, MSTP, PVST, PVST+);
• технологию агрегации интерфейсов и перераспределения нагрузки между ними;
• некоторые вопросы стабильности и безопасности;
• как изменить схему существующей сети, чтобы всем было хорошо.
Кратко обсудим оборудование второго уровня модели OSI. Какие функции оно должно выполнять?
> Запоминание адресов (MAC-таблица);
> Перенаправление (коммутация) пакетов, читай, фреймов;
> Защита от петель (loop) в сети.
Про первое понятно, ведь у каждого коммутатора имеется таблица сопоставления MAC-адресов и портов (т.н. CAM-table — Content Addressable Memory Table), об этом мы уже говорили и повторяли не раз. Коммутатор запоминает MAC-адрес отправителя и порт, с которого пришел фрейм. Теперь коммутатор должен передать фрейм на порт, где находится MAC, указанный в качестве адреса назначения. Но если коммутатор только включили и таблица попросту пуста? Тогда коммутатор отправляет фрейм на все порты кроме порта-источника. Конечные хосты проверяют параметр destination address и если он не совпадает с их, то дропают фрейм. А вот устройство-получатель в ответном кадре указывает свой MAC, и вот уже CAM-таблица пополнилась информацией, теперь коммутатор знает на какой порт слать фреймы с искомым адресом. В следующий раз коммутатор не будет делать широковещательную рассылку, а отправит данные на нужный порт. Содержимое CAM-таблицы можно посмотреть командой show mac address-table, а на коммутаторах фирмы Dlink, например, это делается командой show fdb. Содержимое таблицы не хранится вечно, по-умолчанию у цисок MAC адрес удаляется из таблицы, если к нему не обращались более 300 секунд.
Всё, мы теперь познали дзэн коммутации. А теперь что такое петли?
Часто для повышения отказоустойчивости сети и избежания проблем со связью между свичами используют т.н. избыточные линки (redundant links) — дополнительные соединения. Идея простейшая, если между свичами гаснет один линк, то мы используем запасной. Вау, всё вроде классно, но представим, что два свича соединены двумя проводами:

И вот какой-то рабочей станции, пусть это будет ПК1 приспичило отправить ARP-запрос. Раз ARP, значит широковещательный, и вышестоящий коммутатор отправляет его на все порты кроме исходного.

Второй свич особо не удивляясь смотрит, что получил широковещательный фрейм и тоже шлет его на все порты, в т.ч. и порты-источники (кадр из fa0/24 шлет в fa0/1, и наоборот).

Таким же макаром поступает и первый свич. В итоге мы получаем широковещательный штор (broadcast storm), который намертво блокирует нормальное функционирование сети, т.к. свичи вместо полезной нагрузки кидаются друг в друга мусором. Порты и процессоры уходят в 100% загрузку.

Что ж делать? Мы и штормов не хотим, но и отказоустойчивость за счет дополнительных линков - дело очень важное. Тут то и приходит STP (Spanning Tree Protocol).
Основная задача L2-протокола STP - предотвращение образования петель на канальном уровне. Как это сделать? Да отрубить все избыточные линки, пока они нам не понадобятся. Все гениальное просто. Но тут возникают вопросы.
Какой линк из двух/трех/четырех отрубить?
Как определить, что основной линк упал и надо запускать резервный?
Как понять, что у нас в сети возникла петля?
Давайте подробнее разберем работу STP, тогда и сможет ответить на эти и другие вопросы.
Протокол STP использует так называемый алгоритм STA (Spanning Tree Algorithm), в результате работы которого возникает граф в виде дерева.
Для обмена информацией между собой свичи используют специальные пакеты (может фреймы? прим.), т.н. BPDU (Bridge Protocol Data Units). BPDUшечки бывают двух видов - конфигурационные (Configuration BPDU) и панические типа “ААА, топология поменялась!” TCN (Topology Change Notification BPDU). Первые регулярно рассылает корневой свич (root switch) и их ретранслируют остальные, используя для построения топологии. Вторые же рассылаются при изменении топологии (падении линка, падения одного из свичей).
Рассмотрим важнейшую информацию, которую содержат конфигурационные BPDU:
• идентификатор отправителя (Bridge ID);
• идентификатор корневого свича (Root Bridge ID);
• идентификатор порта, из которого отправлен данный пакет (Port ID);
• стоимость маршрута до корневого свича (Root Path Cost).
Чуть позже разберемся, что всё это такое и зачем оно нужно. Процесс выглядит так, что по-умолчанию каждые 2 секунды устройства шлют на все свои порты BPDU с адресатом в виде мультикастового ethernet-адреса 01-80-c2-00-00-00, и этот фрейм изучают все свичи с включенным STP.
Каким же образом возникает топология без петель?
Для начала происходит выбор корневого свича (в оригинальном определении, моста - root bridge). Данное устройство будет считаться для STP точкой отсчета, центром сети, и всё дерево STP будет сходиться к нему. Выбирается он исходя из идентификатора свича (Bridge ID) - числа из 8 байт, состоящего из Bridge Priority (приоритет, от 0 до 65535, по умолчанию 32768+номер vlan или инстанс MSTP, в зависимости от реализации протокола), и MAC-адреса устройства. При запуске STP каждый коммутатор считает себя корневым, указывая это в BPDU и посылая свой ID как идентификатор корневого свича. Но в случае получения BPDU с меньшим ID, он перестает считать себя рутом, и начинает рассылать уже этот ID в качестве корневого. В итоге рутом становится свич с наименьшим Bridge ID.
Свичи померились своими айдишниками, выбрали рутом тот, у которого он меньше, и... Что теперь? Каждый свич должен выбрать основной порт, который будет "смотреть" в сторону рутового свича. Этот порт очень грамотно назван корневым портом (Root port). Как сделать выбор? Исходя из "стоимости" маршрута до рута от каждого из своих портов. Стоимость будет определяться суммой стоимостей всех линков, которые нужно пройти кадру от исходного свича до корневого. А уже стоимость каждого линка определяется совсем просто - исходя из его скорости (выше скорость - ниже стоимость).
Процесс определения стоимости связан с полем BPDU “Root Path Cost” и выглядит так:
1. Корневой свич рассылает BPDUшку с Root Path Cost равной нулю.
2. Ближайший свич-получатель смотрит на скорость порта, где оказался этот фрейм, и прибавляет к Root Path Cost стоимость согласно таблице:
3. BPDU второго свича будет, которые он разошлет нижестоящим коммутаторам, уже с новым значением Root Path Cost. И далее по цепочке.
В случае одинаковой стоимости конечного пути выбор упадет на меньший порт, и он станет корневым.
Теперь выбираются назначенные (Designated) порты. Естественно, из каждого конкретного сегмента сети должен существовать только один путь к корневому свичу, иначе неминуемо возникнет петля. Тут имеется ввиду физический сегмент, а в современных сетях без глупых хабов это по сути своей просто провод. Назначенным портом будет тот, который имеет лучшую стоимость в данном сегменте. По данному принципу все порты корневого свича - назначенные.
После этого оставшиеся порты блокируются, препятствуя образованию петель:

Мы тут обмолвились о состоянии блокировки порта, но помимо этого порт может находиться и в других агрегатных состояниях...
В обычном 802.1D STP существует пять состояний:
1. Блокировка (blocking): блокированный порт не шлет ничего. Это состояние предназначено, как говорилось выше, для предотвращения петель в сети. Блокированный порт, тем не менее, слушает BPDU (чтобы быть в курсе событий, это позволяет ему, когда надо, разблокироваться и начать работать);
2. Прослушивание (listening): порт слушает и начинает сам отправлять BPDU, кадры с данными не отправляет;
3. Обучение (learning): порт слушает и отправляет BPDU, а также вносит изменения в CAM-таблицу, но данные не перенаправляет;
4. Перенаправление\пересылка (forwarding): этот может все: и посылает\принимает BPDU, и с данными оперирует, и участвует в поддержании таблицы mac-адресов. То есть это обычное состояние рабочего порта;
5. Отключен (disabled): состояние administratively down, отключен командой shutdown. Понятное дело, ничего делать не может вообще, пока вручную не включат.
Порядок перечисления состояний не случаен, при включении коммутатора (также при поднятии нового линка) порты проходят все эти состояния за исключением, понятное дело, пятого. Зачем же такие сложности? STP очень осторожен, ведь на другом конце кабеля может быть свич, а это потенциальная петля. Поэтому сначала порт в течение 15 секунд (по-умолчанию) слушает приходящие на него BPDUшки, осознавая свое положение в сети. Еще 15 секунд порт лёрнит MAC-адреса в свою CAM-таблицу, и только полностью убедившись, что ничего не поломает, начинает нормальную работу. В итоге имеем аж 30 секунд простоя, что вообще говоря крайне нежелательно, даже компьютеры и те быстрее грузятся... Что делать?
Для случаев, когда нет времени на "разогрев" STP существует режим portfast, порт с таким конфигом при активации сразу переходит в статус forwarding. Само собой, данный режим следует включать только на портах, которые смотрят на конечные устройства, но никак не на другие свичи.
Вообще говоря протокол этот очень древний и создавался для работы в пределах LAN. Но у нас то будущее на пороге, повсюду сплошные VLAN, что делать?
Стандарт 802.1Q определяет каким образом вланы передаются внутри транка. Также он определяет один процесс STP для всех VLAN'ов. BPDUшки по вланам передаются нетегированными в качестве native VLAN. Этот вариант STP известен как CST (Common Spanning Tree). Единственный рабочий процесс не так сильно нагружает коммутатор, да и настраивать это проще, но избыточные линки между свичами блокируются во всех вланах, что в целом-то неприемлемо, так еще и не дает возможности балансировки нагрузки.
Циска в этом смысле как всегда отличилась, выкатив свою проприетарную реализацию протокола - PVST (Per-VLAN Spanning Tree), отлично подходящую для работы в сети с несколькими VLAN. В PVST для каждого VLAN запущен свой процесс STP. Во-первых, это позволяет производить гибкую настройку под нужды каждого влана, во-вторых, позволяет использовать балансировку нагрузки за счет того, что конкретный физический линк может быть заблокирован в одном влане, но работать в другом. Минусом этой реализации является, конечно, проприетарность: для функционирования PVST требуется проприетарный же ISL транк между свичами.
Также существует вторая версия этой реализации — PVST+, которая позволяет наладить связь между свичами с CST и PVST, и работает как с ISL-транком, так и с 802.1q. PVST+ это протокол по умолчанию на коммутаторах Cisco.
Всё сказанное ранее относится именно к первой реализации протокола STP, разработанному еще в бородатом 1985 году, а в 1990 данная реализация была включена в стандарт IEEE 802.1D. В силу особенностей того времени перестройка топологии, занимающая по 30-50 секунд, всех вполне устраивала.
Но вот в 2001 году IEEE представляет новый стандарт - RSTP (он же 802.1w, он же Rapid Spanning Tree Protocol, он же Быстрый STP).
Для простоты приведу табличку различий между STP и RSTP.
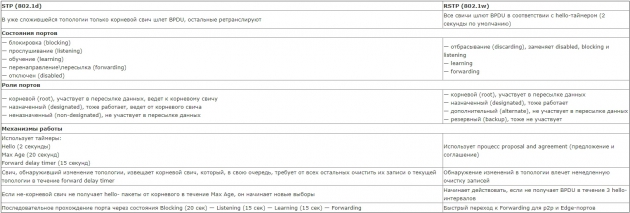
Коротко говоря. У RSTP уменьшилось кол-во состояний порта и, что самое важное, при падении линка не начинается судорожный расчет новой топологии - резерв уже просчитан и линк быстро переключается на запасной. Пограничные порты назначаются, как и раньше, командой spanning-tree portfast, и с ними все понятно- при включении провода сразу переходим к forwarding-состоянию и работаем. Shared-порты работают по старой схеме с прохождением через состояния BLK — LIS — LRN — FWD. А вот на p2p-портах RSTP использует т.н. процесс предложения и соглашения (proposal and agreement).
Не вдаваясь в подробности, его можно описать так: свич справедливо считает, что если линк работает в режиме полного дуплекса, и он не обозначен, как пограничный, значит, на нем только два устройства - он и другой свич. Вместо того, чтобы ждать входящих BPDU, он сам пытается связаться со свичом на том конце провода с помощью специальных proposal BPDU, в которых, конечно, есть информация о стоимости маршрута к корневому свичу. Второй свич сравнивает полученную информацию со своей текущей, и принимает решение, о чем извещает первый свич посредством agreement BPDU.
У цисок RSTP называется PVRST (Per-Vlan Rapid Spanning Tree).
Похожий на PVST протокол, но здесь каждый влан не обязан иметь свой процесс STP, их можно объединять. Вот допустим у нас с вами сеть с 500 вланами, а надо настроить STP только у половины. Это можно сделать с помощью обычного STP, назначив один корневой свич в диапазоне вланов 1-250, а другой - в диапазоне 250-500. Но процессы будут работать для каждого из пятисот вланов по отдельности (хотя действовать будут совершенно одинаково для каждой половины). Логично, что тут хватит и двух процессов. MSTP позволяет создавать столько процесов STP, сколько у нас логических топологий (в данном примере - 2), и распределять по ним вланы. Думаем, нет особого смысла углубляться в теорию и практику MSTP в рамках этой статьи (ибо теории там ого-го), интересующиеся могут пройти по ссылке.
Но какой бы вариант STP мы не использовали, у нас все равно существует так или иначе неработающий линк. А возможно ли задействовать параллельные линки по полной и при этом избежать петель? Да, отвечаем мы вместе с циской, начиная рассказ о EtherChannel.
Иначе это называется link aggregation, link bundling, NIC teaming, port trunkinkg
Технологии агрегации (объединения) каналов выполняют 2 функции: с одной стороны, это объединение пропускной способности нескольких физических линков, а с другой — обеспечение отказоустойчивости соединения (в случае падения одного линка нагрузка переносится на оставшиеся). Объединение линков можно выполнить как вручную (статическое агрегирование), так и с помощью специальных протоколов: LACP (Link Aggregation Control Protocol) и PAgP (Port Aggregation Protocol). LACP, определяемый стандартом IEEE 802.3ad, является открытым стандартом, то есть от вендора оборудования не зависит. Соответственно, PAgP — проприетарная цисковская разработка.
В один такой канал можно объединить до восьми портов. Алгоритм балансировки нагрузки основан на таких параметрах, как IP/MAC-адреса получателей и отправителей и порты. Поэтому в случае возникновения вопроса: “Хей, а чего так плохо балансируется?” в первую очередь смотрите на алгоритм балансировки.
Теперь расскажем вкратце, как обеспечить безопасность сети на втором уровне OSI.
switchport port-security - команда конфигурации интерфейса, включающая защиту на определенном порту свича.
switchport port-security maximum 1 - ограничение количества MAC-адресов, существующих на данном порту. В нашем примере число ограничено одним MAC-адресом.
switchport port-security mac-address адрес - где "адрес" задается вручную. Таким образом мы разрешаем на порту только конкретный MAC.
switchport port-security mac-address sticky - данная модификация команды разрешает MAC, который был на порту в момент ввода команды.
switchport port-security violation {shutdown | restrict | protect} - задание поведения порта в случае нарушения правила.
> shutdown - полное отключение порта, включать обратно надо будет вручную.
> restrict - отбрасывание фреймов с "левыми" MAC-адресами, о чем радостно сообщает в консоль.
> protect - отбрасывание всех фреймов.
Зачем нужна данная функция? Самое очевидное - ограничение количества устройств за портом. Также эта функция защищает нас от атак, связанных с забиванием CAM-таблицы путем рассылки с некого хоста большого количества фреймов с разными MAC-адресами. Далее поведение коммутатора может быть различным, но самое нежелательное - при забивании таблицы MAC-адресов коммутатор начнет слать попадающие на него фреймы как широковещательные на все порты в т.ч. на сетевуху злоумышленника. Данные вашей сети.
Другой вид атаки, связанный с DHCP. Злоумышленники могут развернуть свой DHCP-серверс блэкджеком и шлюхами, который в ответ на широковещательный запрос клиентского устройства будет отдавать в качестве шлюза по умолчанию (а также, например, DNS-сервера) адрес подконтрольной атакующему машины.
Соответственно, весь трафик, направленный за пределы подсети обманутыми устройствами, будет доступен для изучения атакующему — типичная man-in-the-middle атака. Либо такой вариант: подлый мошенник генерируют кучу DHCP-запросов с поддельными MAC-адресами и DHCP-сервер на каждый такой запрос выдаёт IP-адрес до тех пор, пока не истощится пул.
Затем и существует DHCP Snooping - для защиты от подобных атак.
Идея простейшая - указать свичу на каком порту висит настоящий DHCP-сервер, разрешив DHCP-ответы с него и запретив со всех остальных.
ip dhcp snooping - включение данной фичи.
ip dhcp snooping vlan номер(а) - говорим в каких вланах она должна работать.
ip dhcp snooping trust - делаем конкретный порт "доверенным".
Система DHCP Snooping'а после активации начинает вести собственную базу соответствий IP и MAC, обновление и пополнение которой осуществляется за счет прослушивания DHCP запросов/ответов. Данная база позволяет нам противостоять еще одному виду атак - подмене IP-адреса (IP Spoofing). При включенном IP Source Guard, каждый приходящий пакет может проверяться на:
> Соответствие IP-адреса источника адресу, полученному из базы DHCP Snooping (иными словами, айпишник закрепляется за портом свича).
> Соответствие MAC-адреса источника адресу, полученному из базы DHCP Snooping.
ip verify source - включение IP Source Guard на нужном нам интерфейсе. В изначальном виде проверяется только привязка IP-адреса.
ip verify source port-security - данная команда добавляет также проверку по MAC.
Естественно, для непосредственной работы IP Source Guard требуется активированный DHCP Snooping, а для контроля MAC-адресов еще и port-security.
Защита от атак вида ARP-poisoning aka ARP-spoofing. Как мы уже знаем, для того, чтобы узнать MAC-адрес устройства по его IP-адресу, используется проткол ARP: посылается широковещательный запрос вида “у кого ip-адрес 172.16.1.15, ответьте 172.16.1.1”, устройство с айпишником 172.16.1.15 отвечает. Но вместо настоящего хоста с адресом 172.16.1.15 отвечает хост злоумышленника, заставляя таким образом трафик, предназначенный для 172.16.1.15 следовать через него. Для этого и существует Dynamic ARP Inspection.
Схема работы похожа на схему DHCP-Snooping’а: порты делятся на доверенные и недоверенные, на недоверенных каждый ARP-ответ подвергаются анализу: сверяется информация, содержащаяся в этом пакете, с той, которой свич доверяет (либо статически заданные соответствия MAC-IP, либо информация из базы DHCP Snooping). Если не сходится - пакет отбрасывается и генерируется сообщение в syslog.
ip arp inspection vlan номер(а) - включение.
ip arp inspection trust - переводим нужный порт в режим "доверенного".
Перенастраиваем транки:
Сразу внесем соответствующие изменения в документацию.
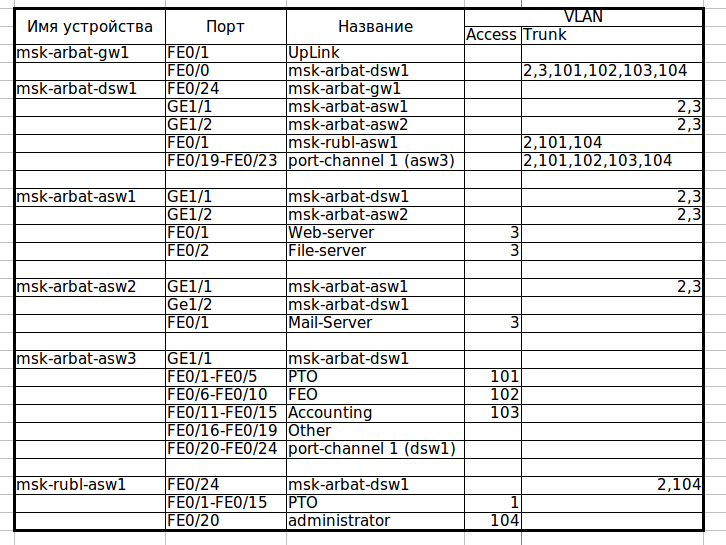
Теперь посмотрим, как в данный момент у нас самонастроился STP. Нас интересует только VLAN0003, где у нас, судя по схеме, петля.
Что мы видим? Давайте разбираться.

Итак, какую информацию мы можем получить? Так как по умолчанию на современных цисках работает PVST+ (т.е. для каждого влана свой процесс STP), и у нас есть более одного влана, выводится информация по каждому влану в отдельности, каждая запись предваряется номером влана. Затем идет вид STP: ieee значит PVST, rstp — Rapid PVST, mstp то и значит. Затем идет секция с информацией о корневом свиче: установленный на нем приоритет, его mac-адрес, стоимость пути от текущего свича до корневого, порт, который был выбран в качестве корневого (имеет лучшую стоимость), а также настройки таймеров STP. Далее- секция с той же информацией о текущем свиче (с которого выполняли команду). Затем - таблица состояния портов, которая состоит из следующих колонок (слева направо):
• собственно, порт;
• его роль (Root- корневой порт, Desg- назначенный порт, Altn- дополнительный, Back- резервный);
• его статус (FWD- работает, BLK- заблокирован, LIS- прослушивание, LRN- обучение);
• стоимость маршрута до корневого свича;
• Port ID в формате: приоритет порта.номер порта;
• тип соединения.
Итак, мы видим, что Gi1/1 - корневой порт, это дает некоторую вероятность того, что на другом конце линка корневой свич. Смотрим по схеме, куда ведет линк: ага, некий msk-arbat-asw1.
Видим мы следующее:
Вот он, наш корневой свич для VLAN0003.
А теперь посмотрим на схему. Ранее, мы увидели в состоянии портов, что dsw1 блокирует порт Gi1/2, разрывая таким образом петлю. Но является ли это оптимальным решением? Нет, конечно. Сейчас наша новая сеть работает точь-в-точь как старая - трафик от asw2 идет только через asw1. Выбор корневого маршрутизатора никогда не нужно оставлять на совесть глупого STP. Исходя из схемы, наиболее оптимальным будет выбор в качестве корневого свича dsw1 - таким образом, STP заблокирует линк между asw1 и asw2. Теперь это все надо объяснить недалекому протоколу. А для него главное что? Bridge ID. И он неслучайно складывается из двух чисел. Приоритет- это как раз то слагаемое, которое отдано на откуп сетевому инженеру, чтобы он мог повлиять на результат выбора корневого свича. Итак, наша задача сводится к тому, чтобы уменьшить (меньше-лучше, думает STP) приоритет нужного свича, чтобы он стал Root Bridge. Есть два пути:
1. Вручную установить приоритет - меньший, нежели текущий.
Теперь для VLAN 3 наш msk-arbat-dsw1 стал корневым, т.к. теперь имеет меньший Bridge ID:
2. Также можно дать железке самой всё решить:
Смотрим:
Мы видим, что железка поставила какой-то странный приоритет. Откуда взялась эта круглая цифра, спросите вы? А все просто - STP смотрит минимальный приоритет (т.е. тот, который у корневого свича), и уменьшает его на два шага инкремента (который составляет 4096, т.е. в итоге 8192). Почему на два? А чтобы была возможность на другом свиче дать команду spanning-tree vlan n root secondary (назначает приоритет=приоритет корневого-4096), что позволит нам быть уверенными, что, если с текущим корневым свичом что-то произойдет, его функции перейдут к этому, “запасному”. Вероятно, вы уже видите на схеме, как лампочка на линке между asw2 и asw1 пожелтела? Это STP разорвал петлю. Причем именно в том месте, в котором мы хотели. Sweet! Зайдем проверим: лампочка — это лампочка, а конфиг — это факт.
Попробуем расширить канал, и на помощь призовем EtherChannel. В данный момент у нас соединение идет от fa0/2 dsw1 на Gi1/1 asw3, отключаем провод. Смотрим, какие порты можем использовать на asw3: ага, fa0/20-24 свободны, кажется. Вот их и возьмем. Со стороны dsw1 пусть будут fa0/19-23. Соединяем порты для EtherChannel между собой. На asw3 у нас на интерфейсах что-то настроено, обычно в таких случаях используется команда конфигурационного режима default interface range fa0/20-24, сбрасывающая настройки порта (или портов, как в нашем случае) в дефолтные.
Можно поотрубать настройки вручную и вообще погасить порты, как говорится, во избежание:
А теперь, магия!
Делаем тоже самое на dsw1:
Теперь поднимаем интерфейсы на asw3, наш EtherChannel готов и занимает теперь аж пять физических линков. В конфиге мы увидим его под названием interface Port-channel 1.
Настраиваем транк (повторить также для dsw1):
Готово!
Стандартная ситуация, вдруг пропала связь до какого-нибудь почтового сервера, не дошли несколько важных писем, а вам прилетел нагоняй. Оказалось, выпал патчик из коммутатора в серверной... Ну, так обычно все и бывает - от того, что в кузнице не было гвоздя.
В этот раз поднимем следующие вопросы:
• проблему широковещательного шторма;
• работу и настройку протокола STP и его модификаций (RSTP, MSTP, PVST, PVST+);
• технологию агрегации интерфейсов и перераспределения нагрузки между ними;
• некоторые вопросы стабильности и безопасности;
• как изменить схему существующей сети, чтобы всем было хорошо.
Кратко обсудим оборудование второго уровня модели OSI. Какие функции оно должно выполнять?
> Запоминание адресов (MAC-таблица);
> Перенаправление (коммутация) пакетов, читай, фреймов;
> Защита от петель (loop) в сети.
Про первое понятно, ведь у каждого коммутатора имеется таблица сопоставления MAC-адресов и портов (т.н. CAM-table — Content Addressable Memory Table), об этом мы уже говорили и повторяли не раз. Коммутатор запоминает MAC-адрес отправителя и порт, с которого пришел фрейм. Теперь коммутатор должен передать фрейм на порт, где находится MAC, указанный в качестве адреса назначения. Но если коммутатор только включили и таблица попросту пуста? Тогда коммутатор отправляет фрейм на все порты кроме порта-источника. Конечные хосты проверяют параметр destination address и если он не совпадает с их, то дропают фрейм. А вот устройство-получатель в ответном кадре указывает свой MAC, и вот уже CAM-таблица пополнилась информацией, теперь коммутатор знает на какой порт слать фреймы с искомым адресом. В следующий раз коммутатор не будет делать широковещательную рассылку, а отправит данные на нужный порт. Содержимое CAM-таблицы можно посмотреть командой show mac address-table, а на коммутаторах фирмы Dlink, например, это делается командой show fdb. Содержимое таблицы не хранится вечно, по-умолчанию у цисок MAC адрес удаляется из таблицы, если к нему не обращались более 300 секунд.
Всё, мы теперь познали дзэн коммутации. А теперь что такое петли?
Широковещательный шторм
Часто для повышения отказоустойчивости сети и избежания проблем со связью между свичами используют т.н. избыточные линки (redundant links) — дополнительные соединения. Идея простейшая, если между свичами гаснет один линк, то мы используем запасной. Вау, всё вроде классно, но представим, что два свича соединены двумя проводами:
И вот какой-то рабочей станции, пусть это будет ПК1 приспичило отправить ARP-запрос. Раз ARP, значит широковещательный, и вышестоящий коммутатор отправляет его на все порты кроме исходного.
Второй свич особо не удивляясь смотрит, что получил широковещательный фрейм и тоже шлет его на все порты, в т.ч. и порты-источники (кадр из fa0/24 шлет в fa0/1, и наоборот).
Таким же макаром поступает и первый свич. В итоге мы получаем широковещательный штор (broadcast storm), который намертво блокирует нормальное функционирование сети, т.к. свичи вместо полезной нагрузки кидаются друг в друга мусором. Порты и процессоры уходят в 100% загрузку.
Что ж делать? Мы и штормов не хотим, но и отказоустойчивость за счет дополнительных линков - дело очень важное. Тут то и приходит STP (Spanning Tree Protocol).
STP
Основная задача L2-протокола STP - предотвращение образования петель на канальном уровне. Как это сделать? Да отрубить все избыточные линки, пока они нам не понадобятся. Все гениальное просто. Но тут возникают вопросы.
Какой линк из двух/трех/четырех отрубить?
Как определить, что основной линк упал и надо запускать резервный?
Как понять, что у нас в сети возникла петля?
Давайте подробнее разберем работу STP, тогда и сможет ответить на эти и другие вопросы.
Протокол STP использует так называемый алгоритм STA (Spanning Tree Algorithm), в результате работы которого возникает граф в виде дерева.
Для обмена информацией между собой свичи используют специальные пакеты (может фреймы? прим.), т.н. BPDU (Bridge Protocol Data Units). BPDUшечки бывают двух видов - конфигурационные (Configuration BPDU) и панические типа “ААА, топология поменялась!” TCN (Topology Change Notification BPDU). Первые регулярно рассылает корневой свич (root switch) и их ретранслируют остальные, используя для построения топологии. Вторые же рассылаются при изменении топологии (падении линка, падения одного из свичей).
Рассмотрим важнейшую информацию, которую содержат конфигурационные BPDU:
• идентификатор отправителя (Bridge ID);
• идентификатор корневого свича (Root Bridge ID);
• идентификатор порта, из которого отправлен данный пакет (Port ID);
• стоимость маршрута до корневого свича (Root Path Cost).
Чуть позже разберемся, что всё это такое и зачем оно нужно. Процесс выглядит так, что по-умолчанию каждые 2 секунды устройства шлют на все свои порты BPDU с адресатом в виде мультикастового ethernet-адреса 01-80-c2-00-00-00, и этот фрейм изучают все свичи с включенным STP.
Каким же образом возникает топология без петель?
Для начала происходит выбор корневого свича (в оригинальном определении, моста - root bridge). Данное устройство будет считаться для STP точкой отсчета, центром сети, и всё дерево STP будет сходиться к нему. Выбирается он исходя из идентификатора свича (Bridge ID) - числа из 8 байт, состоящего из Bridge Priority (приоритет, от 0 до 65535, по умолчанию 32768+номер vlan или инстанс MSTP, в зависимости от реализации протокола), и MAC-адреса устройства. При запуске STP каждый коммутатор считает себя корневым, указывая это в BPDU и посылая свой ID как идентификатор корневого свича. Но в случае получения BPDU с меньшим ID, он перестает считать себя рутом, и начинает рассылать уже этот ID в качестве корневого. В итоге рутом становится свич с наименьшим Bridge ID.
Цитата: Забавный и печальный факт.
При прочих равных по дефолту рутом станет самое старое устройство, т.к. оно с высокой долей вероятности будет иметь более ранний MAC-адрес в сравнении с остальными. Вендоры выдают адреса своим железкам последовательно, а Bridge Priority по-умолчанию у всех одинаковая. В итоге бедный процессов этого свича будет постоянно бешено грузиться, упадет эффективность и его работы и появится шанс появления в сети приколов.
Роли портов.
Свичи померились своими айдишниками, выбрали рутом тот, у которого он меньше, и... Что теперь? Каждый свич должен выбрать основной порт, который будет "смотреть" в сторону рутового свича. Этот порт очень грамотно назван корневым портом (Root port). Как сделать выбор? Исходя из "стоимости" маршрута до рута от каждого из своих портов. Стоимость будет определяться суммой стоимостей всех линков, которые нужно пройти кадру от исходного свича до корневого. А уже стоимость каждого линка определяется совсем просто - исходя из его скорости (выше скорость - ниже стоимость).
Процесс определения стоимости связан с полем BPDU “Root Path Cost” и выглядит так:
1. Корневой свич рассылает BPDUшку с Root Path Cost равной нулю.
2. Ближайший свич-получатель смотрит на скорость порта, где оказался этот фрейм, и прибавляет к Root Path Cost стоимость согласно таблице:
Скорость порта Стоимость STP (802.1d)
10 Mbps 100
100 Mbps 19
1 Gbps 4
10 Gbps 23. BPDU второго свича будет, которые он разошлет нижестоящим коммутаторам, уже с новым значением Root Path Cost. И далее по цепочке.
В случае одинаковой стоимости конечного пути выбор упадет на меньший порт, и он станет корневым.
Теперь выбираются назначенные (Designated) порты. Естественно, из каждого конкретного сегмента сети должен существовать только один путь к корневому свичу, иначе неминуемо возникнет петля. Тут имеется ввиду физический сегмент, а в современных сетях без глупых хабов это по сути своей просто провод. Назначенным портом будет тот, который имеет лучшую стоимость в данном сегменте. По данному принципу все порты корневого свича - назначенные.
После этого оставшиеся порты блокируются, препятствуя образованию петель:
Ах да, на картинке в STP участвуют свичи, в реальности же
этого можно добится установкой дополнительной свичевой платы.
этого можно добится установкой дополнительной свичевой платы.
Состояния портов.
Мы тут обмолвились о состоянии блокировки порта, но помимо этого порт может находиться и в других агрегатных состояниях...
В обычном 802.1D STP существует пять состояний:
1. Блокировка (blocking): блокированный порт не шлет ничего. Это состояние предназначено, как говорилось выше, для предотвращения петель в сети. Блокированный порт, тем не менее, слушает BPDU (чтобы быть в курсе событий, это позволяет ему, когда надо, разблокироваться и начать работать);
2. Прослушивание (listening): порт слушает и начинает сам отправлять BPDU, кадры с данными не отправляет;
3. Обучение (learning): порт слушает и отправляет BPDU, а также вносит изменения в CAM-таблицу, но данные не перенаправляет;
4. Перенаправление\пересылка (forwarding): этот может все: и посылает\принимает BPDU, и с данными оперирует, и участвует в поддержании таблицы mac-адресов. То есть это обычное состояние рабочего порта;
5. Отключен (disabled): состояние administratively down, отключен командой shutdown. Понятное дело, ничего делать не может вообще, пока вручную не включат.
Порядок перечисления состояний не случаен, при включении коммутатора (также при поднятии нового линка) порты проходят все эти состояния за исключением, понятное дело, пятого. Зачем же такие сложности? STP очень осторожен, ведь на другом конце кабеля может быть свич, а это потенциальная петля. Поэтому сначала порт в течение 15 секунд (по-умолчанию) слушает приходящие на него BPDUшки, осознавая свое положение в сети. Еще 15 секунд порт лёрнит MAC-адреса в свою CAM-таблицу, и только полностью убедившись, что ничего не поломает, начинает нормальную работу. В итоге имеем аж 30 секунд простоя, что вообще говоря крайне нежелательно, даже компьютеры и те быстрее грузятся... Что делать?
Portfast.
Для случаев, когда нет времени на "разогрев" STP существует режим portfast, порт с таким конфигом при активации сразу переходит в статус forwarding. Само собой, данный режим следует включать только на портах, которые смотрят на конечные устройства, но никак не на другие свичи.
Цитата: Команда switchport host
Существует очень удобная команда switchport host, служащая для конфигурирования "тупиковых" портов, смотрящих в конечные устройства. Данная команда сразу включает на порту режим portfast, переводит его access и отрубает протокол PAgP (о нём поговорим, когда поднимем тему агрегации).
Виды STP.
Вообще говоря протокол этот очень древний и создавался для работы в пределах LAN. Но у нас то будущее на пороге, повсюду сплошные VLAN, что делать?
Стандарт 802.1Q определяет каким образом вланы передаются внутри транка. Также он определяет один процесс STP для всех VLAN'ов. BPDUшки по вланам передаются нетегированными в качестве native VLAN. Этот вариант STP известен как CST (Common Spanning Tree). Единственный рабочий процесс не так сильно нагружает коммутатор, да и настраивать это проще, но избыточные линки между свичами блокируются во всех вланах, что в целом-то неприемлемо, так еще и не дает возможности балансировки нагрузки.
Циска в этом смысле как всегда отличилась, выкатив свою проприетарную реализацию протокола - PVST (Per-VLAN Spanning Tree), отлично подходящую для работы в сети с несколькими VLAN. В PVST для каждого VLAN запущен свой процесс STP. Во-первых, это позволяет производить гибкую настройку под нужды каждого влана, во-вторых, позволяет использовать балансировку нагрузки за счет того, что конкретный физический линк может быть заблокирован в одном влане, но работать в другом. Минусом этой реализации является, конечно, проприетарность: для функционирования PVST требуется проприетарный же ISL транк между свичами.
Также существует вторая версия этой реализации — PVST+, которая позволяет наладить связь между свичами с CST и PVST, и работает как с ISL-транком, так и с 802.1q. PVST+ это протокол по умолчанию на коммутаторах Cisco.
RSTP.
Всё сказанное ранее относится именно к первой реализации протокола STP, разработанному еще в бородатом 1985 году, а в 1990 данная реализация была включена в стандарт IEEE 802.1D. В силу особенностей того времени перестройка топологии, занимающая по 30-50 секунд, всех вполне устраивала.
Но вот в 2001 году IEEE представляет новый стандарт - RSTP (он же 802.1w, он же Rapid Spanning Tree Protocol, он же Быстрый STP).
Для простоты приведу табличку различий между STP и RSTP.
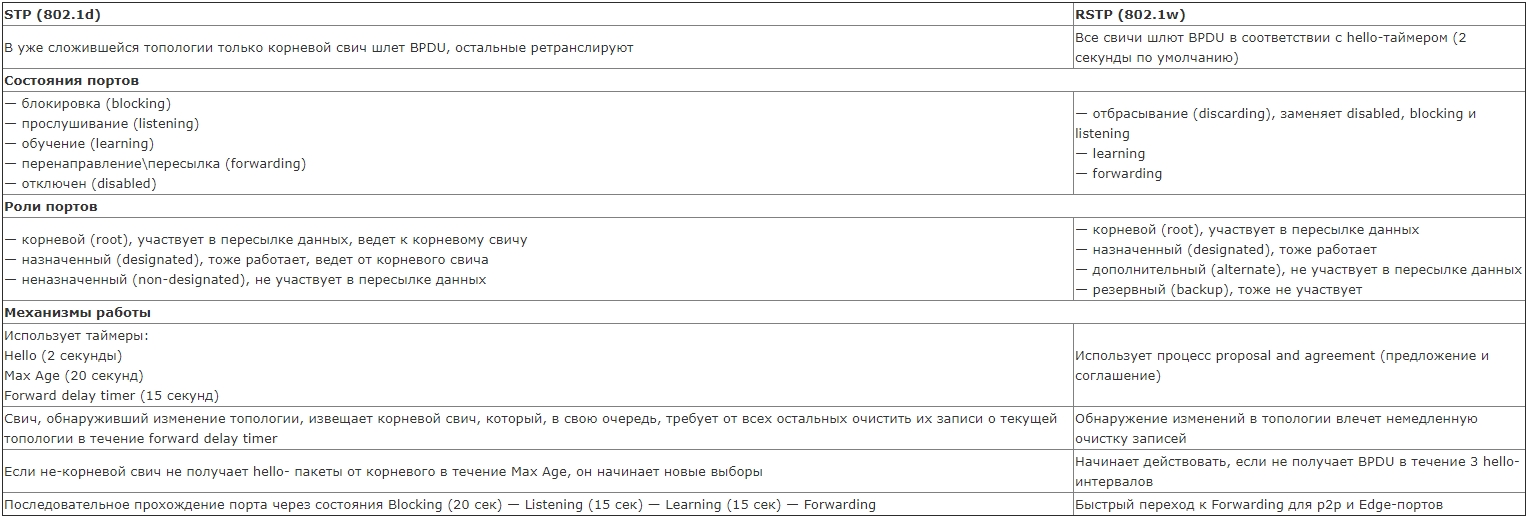
Коротко говоря. У RSTP уменьшилось кол-во состояний порта и, что самое важное, при падении линка не начинается судорожный расчет новой топологии - резерв уже просчитан и линк быстро переключается на запасной. Пограничные порты назначаются, как и раньше, командой spanning-tree portfast, и с ними все понятно- при включении провода сразу переходим к forwarding-состоянию и работаем. Shared-порты работают по старой схеме с прохождением через состояния BLK — LIS — LRN — FWD. А вот на p2p-портах RSTP использует т.н. процесс предложения и соглашения (proposal and agreement).
Не вдаваясь в подробности, его можно описать так: свич справедливо считает, что если линк работает в режиме полного дуплекса, и он не обозначен, как пограничный, значит, на нем только два устройства - он и другой свич. Вместо того, чтобы ждать входящих BPDU, он сам пытается связаться со свичом на том конце провода с помощью специальных proposal BPDU, в которых, конечно, есть информация о стоимости маршрута к корневому свичу. Второй свич сравнивает полученную информацию со своей текущей, и принимает решение, о чем извещает первый свич посредством agreement BPDU.
У цисок RSTP называется PVRST (Per-Vlan Rapid Spanning Tree).
MSTP.
Похожий на PVST протокол, но здесь каждый влан не обязан иметь свой процесс STP, их можно объединять. Вот допустим у нас с вами сеть с 500 вланами, а надо настроить STP только у половины. Это можно сделать с помощью обычного STP, назначив один корневой свич в диапазоне вланов 1-250, а другой - в диапазоне 250-500. Но процессы будут работать для каждого из пятисот вланов по отдельности (хотя действовать будут совершенно одинаково для каждой половины). Логично, что тут хватит и двух процессов. MSTP позволяет создавать столько процесов STP, сколько у нас логических топологий (в данном примере - 2), и распределять по ним вланы. Думаем, нет особого смысла углубляться в теорию и практику MSTP в рамках этой статьи (ибо теории там ого-го), интересующиеся могут пройти по ссылке.
Агрегация каналов.
Но какой бы вариант STP мы не использовали, у нас все равно существует так или иначе неработающий линк. А возможно ли задействовать параллельные линки по полной и при этом избежать петель? Да, отвечаем мы вместе с циской, начиная рассказ о EtherChannel.
Иначе это называется link aggregation, link bundling, NIC teaming, port trunkinkg
Технологии агрегации (объединения) каналов выполняют 2 функции: с одной стороны, это объединение пропускной способности нескольких физических линков, а с другой — обеспечение отказоустойчивости соединения (в случае падения одного линка нагрузка переносится на оставшиеся). Объединение линков можно выполнить как вручную (статическое агрегирование), так и с помощью специальных протоколов: LACP (Link Aggregation Control Protocol) и PAgP (Port Aggregation Protocol). LACP, определяемый стандартом IEEE 802.3ad, является открытым стандартом, то есть от вендора оборудования не зависит. Соответственно, PAgP — проприетарная цисковская разработка.
В один такой канал можно объединить до восьми портов. Алгоритм балансировки нагрузки основан на таких параметрах, как IP/MAC-адреса получателей и отправителей и порты. Поэтому в случае возникновения вопроса: “Хей, а чего так плохо балансируется?” в первую очередь смотрите на алгоритм балансировки.
Port security.
Теперь расскажем вкратце, как обеспечить безопасность сети на втором уровне OSI.
switchport port-security - команда конфигурации интерфейса, включающая защиту на определенном порту свича.
switchport port-security maximum 1 - ограничение количества MAC-адресов, существующих на данном порту. В нашем примере число ограничено одним MAC-адресом.
switchport port-security mac-address адрес - где "адрес" задается вручную. Таким образом мы разрешаем на порту только конкретный MAC.
switchport port-security mac-address sticky - данная модификация команды разрешает MAC, который был на порту в момент ввода команды.
switchport port-security violation {shutdown | restrict | protect} - задание поведения порта в случае нарушения правила.
> shutdown - полное отключение порта, включать обратно надо будет вручную.
> restrict - отбрасывание фреймов с "левыми" MAC-адресами, о чем радостно сообщает в консоль.
> protect - отбрасывание всех фреймов.
Зачем нужна данная функция? Самое очевидное - ограничение количества устройств за портом. Также эта функция защищает нас от атак, связанных с забиванием CAM-таблицы путем рассылки с некого хоста большого количества фреймов с разными MAC-адресами. Далее поведение коммутатора может быть различным, но самое нежелательное - при забивании таблицы MAC-адресов коммутатор начнет слать попадающие на него фреймы как широковещательные на все порты в т.ч. на сетевуху злоумышленника. Данные вашей сети.
DHCP Snooping.
Другой вид атаки, связанный с DHCP. Злоумышленники могут развернуть свой DHCP-сервер
Соответственно, весь трафик, направленный за пределы подсети обманутыми устройствами, будет доступен для изучения атакующему — типичная man-in-the-middle атака. Либо такой вариант: подлый мошенник генерируют кучу DHCP-запросов с поддельными MAC-адресами и DHCP-сервер на каждый такой запрос выдаёт IP-адрес до тех пор, пока не истощится пул.
Затем и существует DHCP Snooping - для защиты от подобных атак.
Идея простейшая - указать свичу на каком порту висит настоящий DHCP-сервер, разрешив DHCP-ответы с него и запретив со всех остальных.
ip dhcp snooping - включение данной фичи.
ip dhcp snooping vlan номер(а) - говорим в каких вланах она должна работать.
ip dhcp snooping trust - делаем конкретный порт "доверенным".

IP Source Guard.
Система DHCP Snooping'а после активации начинает вести собственную базу соответствий IP и MAC, обновление и пополнение которой осуществляется за счет прослушивания DHCP запросов/ответов. Данная база позволяет нам противостоять еще одному виду атак - подмене IP-адреса (IP Spoofing). При включенном IP Source Guard, каждый приходящий пакет может проверяться на:
> Соответствие IP-адреса источника адресу, полученному из базы DHCP Snooping (иными словами, айпишник закрепляется за портом свича).
> Соответствие MAC-адреса источника адресу, полученному из базы DHCP Snooping.
ip verify source - включение IP Source Guard на нужном нам интерфейсе. В изначальном виде проверяется только привязка IP-адреса.
ip verify source port-security - данная команда добавляет также проверку по MAC.
Естественно, для непосредственной работы IP Source Guard требуется активированный DHCP Snooping, а для контроля MAC-адресов еще и port-security.
Dynamic ARP Inspection.
Защита от атак вида ARP-poisoning aka ARP-spoofing. Как мы уже знаем, для того, чтобы узнать MAC-адрес устройства по его IP-адресу, используется проткол ARP: посылается широковещательный запрос вида “у кого ip-адрес 172.16.1.15, ответьте 172.16.1.1”, устройство с айпишником 172.16.1.15 отвечает. Но вместо настоящего хоста с адресом 172.16.1.15 отвечает хост злоумышленника, заставляя таким образом трафик, предназначенный для 172.16.1.15 следовать через него. Для этого и существует Dynamic ARP Inspection.
Схема работы похожа на схему DHCP-Snooping’а: порты делятся на доверенные и недоверенные, на недоверенных каждый ARP-ответ подвергаются анализу: сверяется информация, содержащаяся в этом пакете, с той, которой свич доверяет (либо статически заданные соответствия MAC-IP, либо информация из базы DHCP Snooping). Если не сходится - пакет отбрасывается и генерируется сообщение в syslog.
ip arp inspection vlan номер(а) - включение.
ip arp inspection trust - переводим нужный порт в режим "доверенного".
Практика.
Перенастраиваем транки:
msk-arbat-dsw1(config)#interface gi1/2
msk-arbat-dsw1(config-if)#description msk-arbat-asw2
msk-arbat-dsw1(config-if)#switchport trunk allowed vlan 2,3
msk-arbat-dsw1(config-if)#int fa0/2
msk-arbat-dsw1(config-if)#description msk-arbat-asw3
msk-arbat-dsw1(config-if)#switchport mode trunk
msk-arbat-dsw1(config-if)#switchport trunk allowed vlan 2,101-104
msk-arbat-asw2(config)#int gi1/2
msk-arbat-asw2(config-if)#description msk-arbat-dsw1
msk-arbat-asw2(config-if)#switchport mode trunk
msk-arbat-asw2(config-if)#switchport trunk allowed vlan 2,3
msk-arbat-asw2(config-if)#no shutdownСразу внесем соответствующие изменения в документацию.
Теперь посмотрим, как в данный момент у нас самонастроился STP. Нас интересует только VLAN0003, где у нас, судя по схеме, петля.
msk-arbat-dsw1>enable
msk-arbat-dsw1#show spanning-tree vlan 3Что мы видим? Давайте разбираться.

Итак, какую информацию мы можем получить? Так как по умолчанию на современных цисках работает PVST+ (т.е. для каждого влана свой процесс STP), и у нас есть более одного влана, выводится информация по каждому влану в отдельности, каждая запись предваряется номером влана. Затем идет вид STP: ieee значит PVST, rstp — Rapid PVST, mstp то и значит. Затем идет секция с информацией о корневом свиче: установленный на нем приоритет, его mac-адрес, стоимость пути от текущего свича до корневого, порт, который был выбран в качестве корневого (имеет лучшую стоимость), а также настройки таймеров STP. Далее- секция с той же информацией о текущем свиче (с которого выполняли команду). Затем - таблица состояния портов, которая состоит из следующих колонок (слева направо):
• собственно, порт;
• его роль (Root- корневой порт, Desg- назначенный порт, Altn- дополнительный, Back- резервный);
• его статус (FWD- работает, BLK- заблокирован, LIS- прослушивание, LRN- обучение);
• стоимость маршрута до корневого свича;
• Port ID в формате: приоритет порта.номер порта;
• тип соединения.
Итак, мы видим, что Gi1/1 - корневой порт, это дает некоторую вероятность того, что на другом конце линка корневой свич. Смотрим по схеме, куда ведет линк: ага, некий msk-arbat-asw1.
msk-arbat-asw1#show spanning-tree vlan 3Видим мы следующее:
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 32771
Address 0007.ECC4.09E2
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 secВот он, наш корневой свич для VLAN0003.
А теперь посмотрим на схему. Ранее, мы увидели в состоянии портов, что dsw1 блокирует порт Gi1/2, разрывая таким образом петлю. Но является ли это оптимальным решением? Нет, конечно. Сейчас наша новая сеть работает точь-в-точь как старая - трафик от asw2 идет только через asw1. Выбор корневого маршрутизатора никогда не нужно оставлять на совесть глупого STP. Исходя из схемы, наиболее оптимальным будет выбор в качестве корневого свича dsw1 - таким образом, STP заблокирует линк между asw1 и asw2. Теперь это все надо объяснить недалекому протоколу. А для него главное что? Bridge ID. И он неслучайно складывается из двух чисел. Приоритет- это как раз то слагаемое, которое отдано на откуп сетевому инженеру, чтобы он мог повлиять на результат выбора корневого свича. Итак, наша задача сводится к тому, чтобы уменьшить (меньше-лучше, думает STP) приоритет нужного свича, чтобы он стал Root Bridge. Есть два пути:
1. Вручную установить приоритет - меньший, нежели текущий.
msk-arbat-dsw1>enable
msk-arbat-dsw1#configure terminal
msk-arbat-dsw1(config)#spanning-tree vlan 3 priority ?
<0-61440> bridge priority in increments of 4096
msk-arbat-dsw1(config)#spanning-tree vlan 3 priority 4096Теперь для VLAN 3 наш msk-arbat-dsw1 стал корневым, т.к. теперь имеет меньший Bridge ID:
msk-arbat-dsw1#show spanning-tree vlan 3
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 4099
Address 000B.BE2E.392C
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec2. Также можно дать железке самой всё решить:
msk-arbat-dsw1(config)#spanning-tree vlan 3 root primaryСмотрим:
msk-arbat-dsw1#show spanning-tree vlan 3
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 24579
Address 000B.BE2E.392C
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 secМы видим, что железка поставила какой-то странный приоритет. Откуда взялась эта круглая цифра, спросите вы? А все просто - STP смотрит минимальный приоритет (т.е. тот, который у корневого свича), и уменьшает его на два шага инкремента (который составляет 4096, т.е. в итоге 8192). Почему на два? А чтобы была возможность на другом свиче дать команду spanning-tree vlan n root secondary (назначает приоритет=приоритет корневого-4096), что позволит нам быть уверенными, что, если с текущим корневым свичом что-то произойдет, его функции перейдут к этому, “запасному”. Вероятно, вы уже видите на схеме, как лампочка на линке между asw2 и asw1 пожелтела? Это STP разорвал петлю. Причем именно в том месте, в котором мы хотели. Sweet! Зайдем проверим: лампочка — это лампочка, а конфиг — это факт.
msk-arbat-asw2#show spanning-tree vlan 3
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 24579
Address 000B.BE2E.392C
Cost 4
Port 26(GigabitEthernet1/2)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 32771 (priority 32768 sys-id-ext 3)
Address 000A.F385.D799
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 20
Interface Role Sts Cost Prio.Nbr Type
---------------- ---- --- --------- -------- --------------------------------
Fa0/1 Desg FWD 19 128.1 P2p
Gi1/1 Altn BLK 4 128.25 P2p
Gi1/2 Root FWD 4 128.26 P2pEtherChannel
Попробуем расширить канал, и на помощь призовем EtherChannel. В данный момент у нас соединение идет от fa0/2 dsw1 на Gi1/1 asw3, отключаем провод. Смотрим, какие порты можем использовать на asw3: ага, fa0/20-24 свободны, кажется. Вот их и возьмем. Со стороны dsw1 пусть будут fa0/19-23. Соединяем порты для EtherChannel между собой. На asw3 у нас на интерфейсах что-то настроено, обычно в таких случаях используется команда конфигурационного режима default interface range fa0/20-24, сбрасывающая настройки порта (или портов, как в нашем случае) в дефолтные.
Можно поотрубать настройки вручную и вообще погасить порты, как говорится, во избежание:
msk-arbat-asw3(config)#interface range fa0/20-24
msk-arbat-asw3(config-if-range)#no description
msk-arbat-asw3(config-if-range)#no switchport access vlan
msk-arbat-asw3(config-if-range)#no switchport mode
msk-arbat-asw3(config-if-range)#shutdownА теперь, магия!
msk-arbat-asw3(config-if-range)#channel-group 1 mode onДелаем тоже самое на dsw1:
msk-arbat-dsw1(config)#interface range fa0/19-23
msk-arbat-dsw1(config-if-range)#channel-group 1 mode onТеперь поднимаем интерфейсы на asw3, наш EtherChannel готов и занимает теперь аж пять физических линков. В конфиге мы увидим его под названием interface Port-channel 1.
Настраиваем транк (повторить также для dsw1):
msk-arbat-asw3(config)#int port-channel 1
msk-arbat-asw3(config-if)#switchport mode trunk
msk-arbat-asw3(config-if)#switchport trunk allowed vlan 2,101-104Готово!
Спасибо за труд блогу LinkMeUp и циклу "Сети для самых маленьких".


Комментариев 3