Знакомство с VPN. Три веселых буквы.

Оригинал Сети для самых маленьких
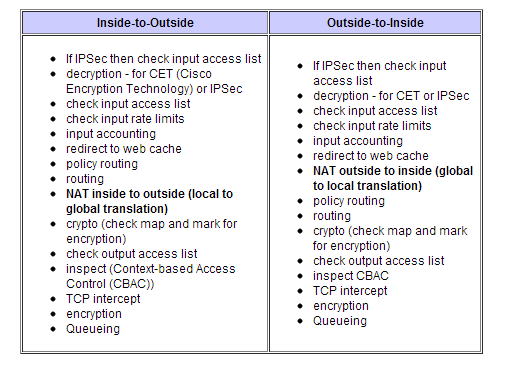
Рассмотрим мы следующие основные моменты.
> Реализации VPN, нюансы применения;
> Т.н. Site-to-Site VPN, и в контексте этого протоколы GRE и IPSec;
> DMVPN совсем уж дикая вещь, расшифровывающаяся как динамическая многоточечная VPN.
Прежде чем бросаться сразу на амбразуры давайте вообще рассмотрим варианты реализации соединения удаленных точек. Конечно, всё зависит от размеров удаленных сетей и собственно расстояния.
Физический канал связи.
1) Ethernet - самая стандартная витая пара. Тут мы ограничены дальностью ~100 метров, т.е. с её помощью можно организовать связь в пределах здания, ну или максимум между двумя близко расположенными строениями. Скорость ограничена 1ГБит/сек (GigabitEthernet) или, учитывая стандарт 10GBASE-T - 10ГБитами/сек.
2) WiFi - здесь уже дальность зависит от используемого стандарта. Теоретически с качественными и дорогими направленными антеннами можно получить устойчивую связь на дистанции ~40 км. Но лучше рассчитывайте на куда более скромные цифры - 5 км в условиях прямой видимости точек. Опять таки скорость зависит от используемого стандарта, расстояния и атмосферных условий (например, от осадков). Если делать всё официально, то вдобавок этот способ требует регистрации у "Роскомнадзора", и это как минимум.
3) xDSL - здесь используется медянка из двух-четырех проводов. Расстояние теоретически будет до 6 км, а скорость в идеальных (читай - никогда) условиях до 250МБит/сек. Можно почитать о разработках, позволяющих получить на двух проводах скорость до 1ГБита, но не очень рассчитывайте на это. Еще существуют специфические решения типа кабельных связок модем-модем, а-ля мост.
4) Радиорелейная связь - несколько десятков километров дистанции и скорости до 600МБит, но это решение уровня оператора или крупного провайдера, т.к. потребуется немало мер по согласованию и планированию, а также подготовке к эксплуатации.
5) Оптоволокно - честная скорость до 1ГБита (да-да, есть решения 10Гбит и даже 100Гбит, но пока это решения операторского уровня и стоят зачастую слишком дорого). В зависимости от кабеля, количества стыков на нем (сварок, кроссов) и конечных приемо-передатчиков (медиаконвертеров или SFP-модулей). Но это опять таки требует согласований, планирования и квалификации от работников (можно взять и рукожопых подрядчиков, но результат будет соответствующим). Расстояния от нескольких километров до многих десятков.
Плюс для любого из этих вариантов в том, что это именно ваша физическая линия. Вы вольны нагружать её, использовать как вам это необходимо и только на вас (и форсмажорах) лежит ответственность за её работоспособность.
Аренда канала.
Для организации стабильного канала, например, между городами это самый правильный вариант. Простой и надежный. Аренда в 99.9% случаев подразумевает входящий в её стоимость ремонт и модернизацию линии в случае... В любом случае. Тем самым вы снимаете с себя одну головную боль, ответственность за работу линии лежит не на вас. Но это не отменяет факта, что вас вы*издят при падении основного канала, если вами не было настроено резервирование.
 sad but true
sad but trueКакие бывают в данном случае варианты?
1) Кабель. Натурально вот прямой кабель. К примеру, пров может выделить вам одно-два волокна в модуле или даже целый модуль в магистральном кабеле. Всё, что хотите, только платите деньги. Это по сути равносильно нашему первому варианту. Это именно Ваш кабель и вы вольны им распоряжаться, гонять трафик хоть до посинения. Провайдер это никак не контролирует, а только осуществляет техническую поддержку линии в рамках вашего с ним договора аренды. Короче говоря, вам не придется судорожно искать подрядчика со сварочником в случае обрыва оптики. Опять таки, за время простоя ответственность несет провайдер. На самом деле такой вариант не из дешевых, имеет смысл искать такой вариант на основе бартера, т.е. некого взаимовыгодного сотрудничества.
2) L2VPN. Фактически это аналогичное решение. Канал также исключительно ваш, но теперь трафик льётся через активное коммуникационное оборудование провайдера, поэтому вполне возможен вариант ограничения ширины канала, например. Это термин собирательный, в него входит несколько вариантов L2-уровня.
• Вам могут предоставить отдельный VLAN, прокинутый между конечными точками.
• Это может быть PWE3, технология использования псевдокабеля, вариант предоставления услуги связи точка-точка, словно у вас действительно проложен цельный кабель. Фреймы информации будут передаваться без изменений. Происходит это потому что на маршрутизаторе провайдера ваш фрейм инкапсулируется PDU вышестоящего уровня (обычно в MPLS.
• Ах да, есть еще вариант - VPLS или виртуальная частная сеть, являющаяся по сути своей симуляцией локальной сети (чтобы было понятнее - возможно сталкивались с сервисом Hamachi? Принцип похож.). В этом варианте существования сеть провайдера является по сути одним большим коммутатором. У него будет своя таблица MAC-адресов и он также будет принимать решения об отправке фреймов исходя из неё. Реализуется также посредством их инкапсуляции в MPLS-пакеты.
2) L3VPN. Это несколько иной случай. Здесь сеть провайдера представляет из себя один большой маршрутизатор с множеством интерфейсов. В данном случае стык у нас происходит уже на сетевом уровне. С клиентской стороны настраиваются IP-адреса на конечных маршрутизаторах с обеих сторон, а настройка маршрутизации внутри сети провайдера уже не ваша головная боль. Назначение IP на точках стыка зависит от реализации проекта, они могут назначаться вами или же провайдером. Работоспособность может быть организована протоколами GRE (вот конкретика на вики), IPSec или уже известного нам MPLS.
С клиентской точки зрения услуга крайне проста, но вот настройка и реализация на стороне провайдера может оказаться весьма нетривиальной задачей. Не волнуйтесь, мы поднимем вопрос подъёма L2/L3VPN по протоколу MPLS, но несколько позже.
Туннель через публичную сеть.
Расклад такой: на обоих наших точках есть выход в интернет, а средств на развертывание чего-то крутого у нас нет. В итоге самым оптимальным вариантом становится поднять туннель между этими самыми точками. Что для этого нужно? Белые (т.е. публичные) статические IP-адреса с обоих сторон (хотя можно и на одной) и соответствующее сетевое оборудование. Да, решение не оптимальное и имеет свои недостатки. О них мы тоже поговорим. Но сейчас рассмотрим именно этот вариант.
В нашем практикуме мы будем соединять по схеме hub and spoke (звезда) три офиса - в Новосибирске, Томске и Брно (пойдем по загранице):
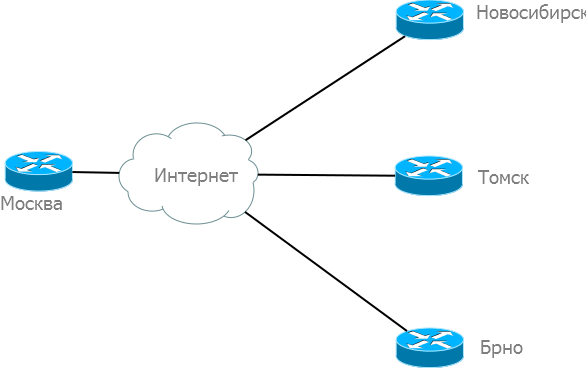
А схема в целом у нас на данный момент выглядит вот так:
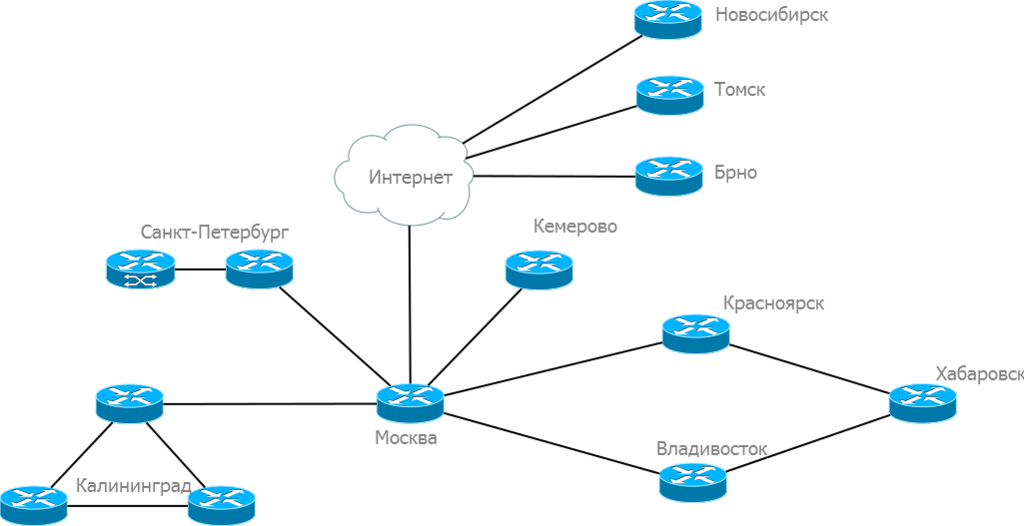
Но всю целиком мы не будем её рассматривать, нам нужно сосредоточиться на конкретике. Мы решили строить туннель, тогда давайте разбираться, что нам предлагают современные решения. Приложений и протоколов для организации VPN туннелей точка-точка существует воз и маленькая тележка, но по большей части они служат для подключения хостов, а не целых сетей. То есть, чтобы сотрудники могли без труда подключаться к корпоративной сети удаленно (у Cisco это зовется teleworker). Мы же подразумеваем полноценную удаленную работу, поэтому нас и занимает вопрос подключения сетей.
Что мы рассмотрим? Конечно, очередной ворох протоколов.
-> GRE
-> IPSec (туннельный и транспортный режимы)
-> GRE over IPSec
-> VTI
-> DMVN
GRE
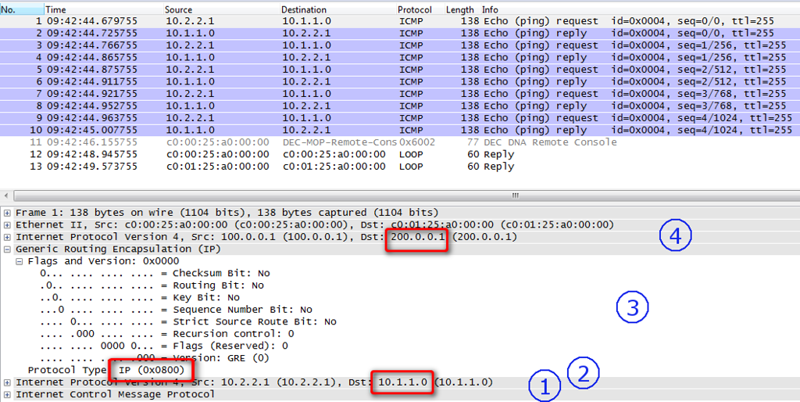
Или же для лучшего понимания, Generic Routing Encapsulation, довольно таки просто протокол тунеллирования... Про... стой?.. А что это вообще такое? Ту-нел-ли-ро... ва-ни-е? Давайте разбираться. Итак наши данные с заголовками (уровня IP, реже Ethernet или ATM) в неизменном виде инкапсулируются в пакет и передаются в публичные интернеты. По месту назначения скидываются лишние заголовки этого пакета скидываются и ваши данные предстают в изначальном виде. В принципе несложно. Но вот давайте подробнее разбираться на примере протокола GRE.
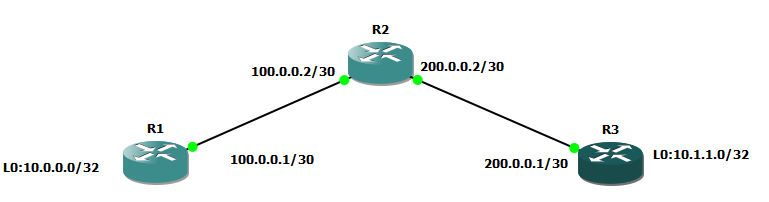
Представим в нашей голове вот такую упрощенную сеточку:

У нас имеются два маршрутизатора, которые смотрят во всемирную паутины белыми публичными айпишниками, а за ними развернуты приватные сетки из диапазона 10.0.0.0/8, о маршрутизации которых в публичной сети речи, конечно, нет. Да, на рисунке у нас два компьютера, но по факту будет происходить настройка виртуального Loopback-интерфейса.
Нам с вами нужно поднять вот такой туннель:
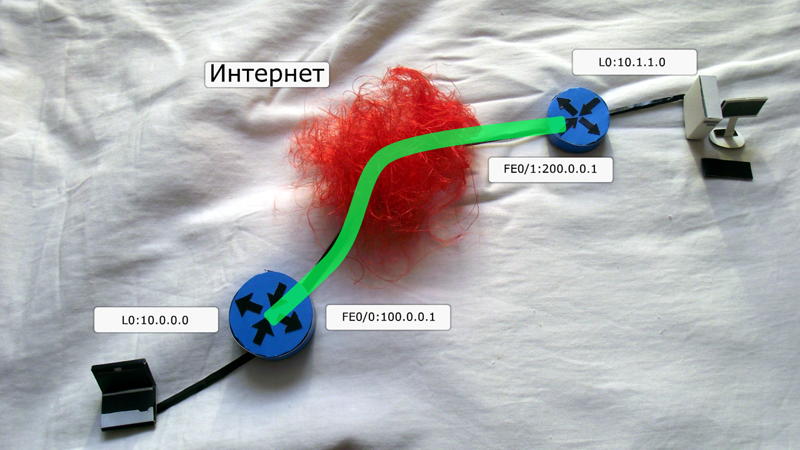
При такой реализации для указанных компьютеров они будут находится в единой локальной сети.
Туннельчик GRE ты будем настраивать так:
interface Tunnel0
ip address 10.2.2.1 255.255.255.252Он является виртуальным интерфейсом L3, и через него у нас будет происходить вся маршрутизация, поэтому IP-адрес ему будет задаваться исходя из составленного плана (из приватной сети). Здесь в качестве source address может быть IP-адрес выходного интерфейса (белый, который нам выдал провайдер) так и его имя - Fe0/0, если брать наш пример.
tunnel source 100.0.0.1А destination address - публичный адрес удаленной точки:
tunnel destination 200.0.0.1В итоге выглядит составленный нами конфиг сейчас будет так:
interface Tunnel0
ip address 10.2.2.1 255.255.255.252
tunnel source 100.0.0.1
tunnel destination 200.0.0.1После этого туннель должен подняться примерно в таком виде:
R1#sh int tun 0
Tunnel0 is up, line protocol is up
Hardware is Tunnel
Internet address is 10.2.2.1/30
MTU 1514 bytes, BW 9 Kbit, DLY 500000 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation TUNNEL, loopback not set
Keepalive not set
Tunnel source 100.0.0.1, destination 200.0.0.1
Tunnel protocol/transport GRE/IPТут всё прозрачно, особо объяснять ничего не нужно. Разве что обратите внимание на MTU, значение которого не равно стандартным 1500, почему - об этом здесь, но чуть позднее.
Примечание. Наш протокол GRE не проверяет, доступен ли вообще destination address, а радостно рапортует, что Tunnel0 is up. Но всё меняется, если добавить в конфиг тоннеля параметр keepalive X, где нужно задать периодичность отсылки проверочных пакетов. Без полученного положительного ответа он не поднимется.
Схема у нас тестовая, поэтому вместо целой локалки у нас просто Loopback-интерфейсы, которые всегда активны, и выдали им адреса из /32 сетки. В реальности вместо них будут полноценные локальные сети.
interface Loopback0
ip address 10.0.0.0 255.255.255.255Пропишем на маршрутизаторе статические маршруты:
ip route 0.0.0.0 0.0.0.0 100.0.0.2
ip route 10.1.1.0 255.255.255.255 10.2.2.2С первым понятно, он означает, что шлюзом по-умолчанию (Default Gateway) у нас будет 100.0.0.2:
R1#traceroute 200.0.0.1
Type escape sequence to abort.
Tracing the route to 200.0.0.1
1 100.0.0.2 56 msec 48 msec 36 msec
2 200.0.0.1 64 msec * 60 msecВторой маршрут рулит пакетами с destination address 10.1.1.0, он посылает их на next-hop 10.2.2.2, адрес интерфейса с другой стороны.
Да, стоит учитывать, что туннели по протоколу GRE однонаправленные, т.е. в стандартной ситуации нужно поднять симметричный интерфейс с другой стороны. Конечно, это не всегда нужно, но у нас ведь задача организовать единую локальную сеть, а значит настраиваем второй роутер:
nsk-obsea-gw1:
interface Tunnel0
ip address 10.2.2.2 255.255.255.252
tunnel source 200.0.0.1
tunnel destination 100.0.0.1
ip route 0.0.0.0 0.0.0.0 200.0.0.2
ip route 10.0.0.0 255.255.255.255 10.2.2.1Что ж, запустим пинги для проверки:
R1#ping 10.1.1.0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.1.1.0, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 44/71/136 ms
R1#tracer 10.1.1.0
Type escape sequence to abort.
Tracing the route to 10.1.1.0
1 10.2.2.2 68 msec * 80 msecЗаработало. Но давайте разберемся с деталями процесса.
1) Итак, вот мы запускаем пинг до 10.1.1.0, тогда маршрутизатор формирует пакет следующего вида:

2) Теперь он заглядывает в свою таблицу маршрутизации:
R1#sh ip route 10.1.1.0
Routing entry for 10.1.1.0/32
Known via «static», distance 1, metric 0
Routing Descriptor Blocks:
* 10.2.2.2
Route metric is 0, traffic share count is 1И рекурсивно разбирается, где находится адрес 10.2.2.2:
R1#sh ip rou 10.2.2.2
Routing entry for 10.2.2.0/30
Known via «connected», distance 0, metric 0 (connected, via interface)
Routing Descriptor Blocks:
* directly connected, via Tunnel0
Route metric is 0, traffic share count is 1Отлично, он понял, что адрес за туннелем - directly connected, via Tunnel0.
R1#sh int tun 0
Tunnel0 is up, line protocol is up
Hardware is Tunnel
Internet address is 10.2.2.1/30
MTU 1514 bytes, BW 9 Kbit, DLY 500000 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation TUNNEL, loopback not set
Keepalive not set
Tunnel source 100.0.0.1, destination 200.0.0.1Адреса налицо: Tunnel source 100.0.0.1, destination 200.0.0.1
3) Маршрутизатор определяет его как GRE-туннель и добавляет пакету соответствующий заголовок:

А поверх всего этого безобразия новый заголовок с IP. Отправителем будет tunnel source, получателем - tunnel destination.

4) Пакет уходит искать друзей по дефолтному маршруту:
R1#sh ip route
Gateway of last resort is 100.0.0.2 to network 0.0.0.05) Не стоит забывать про Ethernet-заголовок, без него не обойтись при отправке пакета в путешествие к провайдеру.
GRE-туннель является виртуальным интерфейсом L3-уровня, поэтому у него имеется свой MAC-адрес (как и у Loopback, кстати). Итогом марлезонского балета станет уход фрейма с интерфейса FastEthernet0/0:
R1#sh ip route 100.0.0.2
Routing entry for 100.0.0.0/30
Known via «connected», distance 0, metric 0 (connected, via interface)
Routing Descriptor Blocks:
* directly connected, via FastEthernet0/0
Route metric is 0, traffic share count is 1О чем свидетельствует directly connected, via FastEthernet0/0. Его то он и укажет в качестве Source MAC:
R1#sh int
FastEthernet0/0 is up, line protocol is up
Hardware is Gt96k FE, address is c000.25a0.0000 (bia c000.25a0.0000)
Internet address is 100.0.0.1/30Этот самый c000.25a0.0000. А destination address мы возьмем у 100.0.0.2 путем ARP-запроса или поковырявшись в ARP-кэше (вдруг он там уже есть):
R1#show arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 100.0.0.1 – c000.25a0.0000 ARPA FastEthernet0/0
Internet 100.0.0.2 71 c001.25a0.0000 ARPA FastEthernet0/0Замечательно - c001.25a0.0000. Так будет выглядеть итоговый фрейм:

6) Именно в таком виде IP-пакет уйдет в интернет. При путешествии через маршрутизаторы сети пакет не будет совсем уж препарироваться, его судьба будет определяться на основе первичного заголовка IP, ваши приватные 10.1.1.0 и 10.0.0.0 по пути никуда не вылезут.
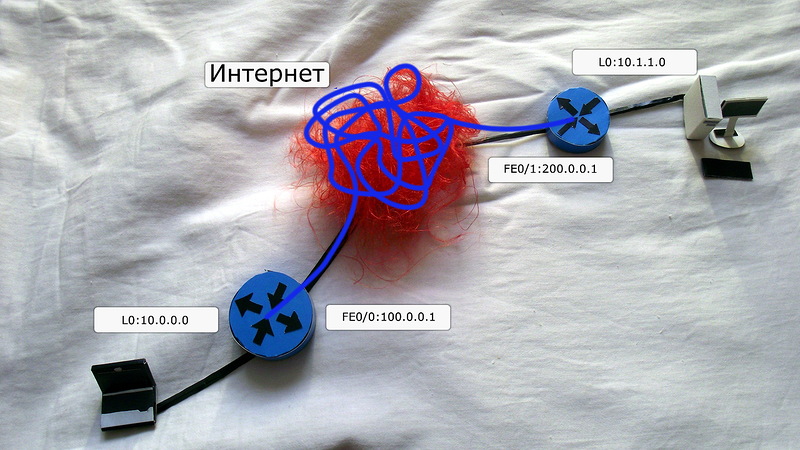
7) В конце концов пакет доберется до другой стороны туннеля. Маршрутизатор R3 обнаруживает в заголовке, что destination address является его собственным, снимает этот заголовок и обнаруживает уже GRE-заголовок. Он проверяет наличие у себя GRE-туннеля, после чего снимает уже и GRE-заголовок. Всё. Теперь перед нами самый обычный IP-пакет, судьбой которого уже распорядятся записи в таблице маршрутизации.
У нас он отправится к интерфейсу Loopback 0
R3#sh ip route 10.1.1.0
Routing entry for 10.1.1.0/32
Known via «connected», distance 0, metric 0 (connected, via interface)
Routing Descriptor Blocks:
* directly connected, via Loopback0
Route metric is 0, traffic share count is 1Т.к. directly connected, via Loopback0
Пребывая в локальной сети пакет будет представлять из себя это:

Обработка будет происходить исходя из приватных IP. При попадании в публичную сетку GRE накинет ему заголовок:

И обработка уже произойдет основываясь на публичных IP.
В интернете пакет выглядит так:
Тут мы видим изначальные данные (1), внутренний IP-заголовок (2), GRE-заголовок с указанием содержимого (3) и внешний IP-заголовок с адресами туннеля (4).

Не уверен, что требуется разжевывать концепт работы протокола, но всё же. Вот вы едете из одного города инкапсулированные в автомобиль, но чтобы попасть в другой город вам нужно преодолеть реку. Делается это с помощью парома, в который инкапсулируется ваш автомобиль. Вот GRE-это паром, а мы с вами быдло-сетевеки.
Несколько важных замечаний!
1. Взятые в нашем примере интерфейсы Loopback и /32 сетки взяты нами исключительно ради теста. Абсолютно с тем же успехом ими могли быть интерфейсы типа Fa1/0.15 и Fa0/1.16 с подсетями за ними 172.16.15.0/24 и 172.16.16.0/24. Или же любые другие интерфейсы и сети.
2. Мы рассуждали о поднятии туннеля сквозь публичную сеть, но организация подобных туннелей возможна и в какой-нибудь корпоративной сетки даже при условии наличия IP-связности между конечными сетями и без туннеля.
3. Да, в теории обратный трафик может вернуться и не по прокинутому туннелю, но поднять симметричный конфиг нужно для возможности декапсуляции GRE-пакетов конечным маршрутизатором.
GRE - пример легко настраиваемого туннеля без особых заморочек в плане эксплуатации и поиска косяков в перспективе. Но давайте сразу о возможных проблемах при его использовании:
1. Передаваемые данные находятся в незашифрованном виде. Отсутствие безопасности по определению.
2. Большие проблемы при масштабировании. Да, связать пять-шесть узлов туннелями и проводить их обслуживание/мониторинг вполне посильная задача. А если таких узлов больше полусотни? Опять же тунеллируемый трафик гоняется через CPU, а это лишняя нагрузка на процы маршрутизаторов.
3. Взаимодействие между конечными точками будет происходить через центральный узел, а не напрямую.
Едем дальше.
IPSec
Это решение проблемы безопасности. Шифрование.
Для организации шифрованного VPN-туннеля используются следующие протоколы и их наборы: IPsec (IP Security), OpenVPN и PPTP (Point-to-Point Tunneling Protocol).
В большинстве случаев выбор падает на IPSec, поэтому будем обсуждать именно его.
В чистом виде IPSec - это просто стандарт, объединяющий несколько протоколов. Перечислим их.
ESP (Encapsulating Security Payload) - безопасная инкапсуляция полезной нагрузки. На нем лежит ответственность за шифрование данных и проверка их целостности, а также аутентификация источника.
AH (Authentication Header) - заголовок аутентификации. Работает над аутентификацией источника и целостностью данных.
IKE (Internet Key Exchange protocol) - протокол обмена ключами. Он используется для образования IPSec SA (Security Association), которую мы обсудим ниже. Его задача - организация согласованной работы участников шифрованного соединения. Благодаря этому протоколу участники узнают об используемом алгоритме шифрования, проверки целостности и взаимной аутентификации.
Но разберемся с тем, что же такое Security Association. Это набор параметров защищенного соединения (самый минимум - алгоритма шифрования и ключа шифрования), которые будут участниками этого самого соединения эксплуатироваться. Таким образом каждое соединение имеет свою ассоциированную конкретно с ним SA.
Теперь разберемся с алгоритмом создания IPSec-соединения.
-> Можно сказать нулевой шаг. Катализатором всего процесса служит попадание некого трафика в соответствие access list'а в crypto map'е. А уже после этого начинается волшебство.
-> Сначала запускается протокол IKE, который позволяет участникам процесса договориться об используемых алгоритмах и механизмах защиты.
<> Происходит взаимная аутентификация и договариваются о поднятии специального соединения, задачей которого будет прогнать информацию об алгоритмах шифрования и других деталях функционирования IPSec-туннеля. Параметры этого защищенного туннельчика (ISAKMP Tunnel, если по науке) определяются политиками ISAKMP, которые можно настраивать из режима конфига по команде crypto isakmp policy номер_политики. Если стороны таки договорились, то поднимется ISAKMP-туннель (проверить его наличие можно командой show crypto isakmp sa). Дальше наступает вторая фаза IKE.
<> Происходит "обсуждение" налаживания основного туннеля. Происходит выбор среди вариантов указанных в crypto ipsec transform-set и после согласования поднимается туннель. При этом технологический ISAKMP-туннель не схлопывается, т.к. будет задействован при обновлении/изменении SA основного. Почему так? Ключи шифрования у IPSec-туннеля имеют конечное время жизни (измеряться может в байтах или секундах, в зависимости от того, что истечет быстрее), по прошествии которого должна произойти их смена. По сути это словно пароль, который меняется раз в час, т.к. по дефолту живет ключ (lifetime IPSec SA) 4608000 килобайт или 3600 секунд.
-> Шифрованный туннель поднят, его параметры всех устраивают и туда начинают литься данные, которые требуется зашифровать (какие именно, это описано в аксесс-листе crypto map).
-> С некоторым периодом отраженным в lifetime обновляются ключи шифрования основного туннеля. Партнеры по IPSec связываются посредством ISAKMP-туннеля и ставят новые SA.
Теперь давайте обсудим следующий момент. Трансформ-сет и отличия между ESP/AH. Шифрование данных при прохождении через туннель определяет команда crypto ipsec transform-set имя_сета, за которой следует название использующегося протокола и алгоритм его работы.
Вот пример:
crypto ipsec transform-set SET1 esp-aesСледуя данной команде маршрутизатор поймет, что трансформ-сет с именем SET1 при использовании будет работать по протоколу ESP с алгоритмом шифрования AES. Ладно, с ESP ничего особенно сложного, он обеспечивает конфиденциальность информации путем её шифрования, а что же такое AH? А вот AH обеспечивает аутентификацию, чтобы на другом конце туннеля всегда были уверены в достоверности данных и правильности отправителя (может быть по пути данные были перехвачены и изменены). Мы сейчас не будем залезать в самую глубь процесса, а коснемся принципа только в двух словах.
В каждый пакет между заголовками транспортного и сетевого уровня вставляется AH-заголовок, в него при этом входит:
• Информация, благодаря которой получатель (читай, адресат) может определить к какой SA пакет относится конкретный пакет. Например, в этих директивах определяется алгоритм чтения хеша, тот же MD5 или SHA.
• Сюда же отнесем ICV (Integrity Check Value), хеш-сумма пакета. Конечно, не всего пакета, а выбранных неизменяемых в процессе транспортировки полей. Сравнение вычисленной хеш-суммы с хранящейся в соответствующем поле позволяет точно быть уверенными, что пакет не подвергался изменениям на пути между отправителем и получателем.
Существует два режима работы набора протоколов IPSec - туннельный и транспортный.
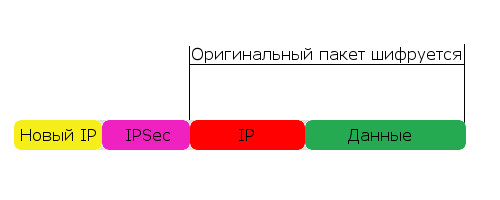
Туннельный режим работы IPSec
Как работает этот режим? Берется ваш оригинальный IP-пакет, полностью шифруется вместе с самим IP-заголовком, к нему добавляется служебная информация IPSec и новый IP-заголовок. Схематично выглядит это так:
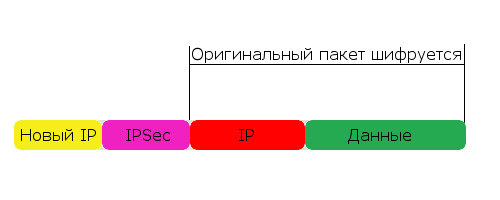
Схема очень обобщенная, отображено здесь только нужное для нашего контекста. На деле заголовков тут куда больше, да еще и трейлеры в конце пакета присутсвуют.
В данном режиме IPSec работает по-умолчанию. Проще всего разобраться во всем уже в процессе настройки. Поехали.
На локальной стороне настройку следует начать с конфигурирования вспомогательного туннеля, это тип шифрования (по дефолту будет DES) и аутентификации, которую можно запилить с сертификатами, но мы будем идти простым методом и установим предварительный ключ.
crypto isakmp policy 1
encr aes
authentication pre-shareВообще говоря, политик может быть далеко не одна. Можно создать целый их ворох, при этом номер политики будет отражать и порядок её рассмотрения (всё зависит от инициатора соединения). Начинается проверка с первого номера, и в случае несовпадения на обеих сторонах идем проверять дальше. Самой безопасной следует сделать первую.
Тут мы укажем pre-shared key, чтобы убедиться в подлинности инициатора 200.0.0.1
crypto isakmp key CISCO address 200.0.0.1Переходим к алгоритмам обработки трафика. Это будет AES-шифрование с ESP-заголовками и алгоритм аутентификации.
crypto ipsec transform-set AES128-SHA esp-aes esp-sha-hmacУказываем мы не конкретный протокол, а целый набор, объединенный в transform-set. Когда поднимается IPSec-сессия, происходит обмен этими сетами, и они должны совпасть.
Чтобы было проще потом разбираться с возможными проблемами лучше называйте transform-set'ы исходя из входящих туда протоколов.
Создаем и настраиваем карту шифрования (crypto-map):
crypto map MAP1 10 ipsec-isakmp
set peer 200.0.0.1
set transform-set AES128-SHA
match address 101Здесь и устанавливается IP-адрес соседа по туннелю, в нашем случае это 200.0.0.1. Сюда же накидываем набор протоколов и access list'ы, которые будут определять, какой трафик станет шифроваться и отправляться по туннелю. У нас это будет так:
access-list 101 permit ip host 10.0.0.0 host 10.1.1.0К созданию ACL для туннеля следует отнестись очень внимательно, т.к. они определяют правила не только для исходящего, но и для входящего трафика. Со списком доступа для NAT, допустим, всё иначе. Что это означает для нас? Всё очень просто, придут пакеты не с IP 10.1.1.0, а с 10.2.2.2, а их никто не станет дешифровывать и просто завернут на входе в туннель.
Еще раз, вот мы гоняем трафик с хоста из сети 10.0.0.0 на 10.1.1.0, то ходить через туннель туда-сюда будет только он, остальной трафик уйдет на другие маршруты.
Примечание. Шифрование происходит уже после маршрутизации, перед самой отправкой пакета. Почему это так важно? Дело в том, что маршрута до указанного публичного пира 200.0.0.1 нам будет мало, нужен маршрут именно до приватного 10.1.1.0 (любой, хоть дефолтный), в противном случае пакет будет дропнут, следуя стандартным правилам маршрутизации. Да, кажется слегка бредовым, но трафик в локальную сеть должен рутиться в глобальные интернеты. Пакеты с приватными IP-заголовками перед самой отправкой к провайдеру (и закономерным дропом там) шифруются и получают уже публичные IP-заголовки. Можно здесь почитать, как при этом производится обработка трафика.
Осталось привязать карту шифрования к конкретному интерфейсу. Ничего не взлетит, пока мы этого не сделаем:
interface FastEthernet0/0
crypto map MAP1С ответной стороны нужно произвести идентичные же настройки. Накатим на наш маршрутизатор R3 такой конфиг:
crypto isakmp policy 1
encr aes
authentication pre-share
crypto isakmp key CISCO address 100.0.0.1
!
!
crypto ipsec transform-set AES128-SHA esp-aes esp-sha-hmac
!
crypto map MAP1 10 ipsec-isakmp
set peer 100.0.0.1
set transform-set AES128-SHA
match address 101
interface FastEthernet0/1
crypto map MAP1
access-list 101 permit ip host 10.1.1.0 host 10.0.0.0
Готово, но... Поглядите в show crypto session и show crypto isakmp sa - увидите неутешительное Down. Не поднимается наш туннель. Проверим счётчики show crypto ipsec sa - ничего.
R1#sh crypto session
Crypto session current status
Interface: FastEthernet0/0
Session status: DOWN
Peer: 200.0.0.1 port 500
IPSEC FLOW: permit ip host 10.0.0.0 host 10.1.1.0
Active SAs: 0, origin: crypto map
R1#sh crypto isakmp sa
dst src state conn-id slot statusОтчего так грустно? Просто по туннелю для его активизации нужно запулить какой-то трафик, хотя бы ICMP-пакетики:
R1#ping 10.1.1.0 source 10.0.0.0
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.1.1.0, timeout is 2 seconds:
Packet sent with a source address of 10.0.0.0
.!!!
Success rate is 80 percent (4/5), round-trip min/avg/max = 60/94/160 msИ проверяем, не изменилась ли ситуация:
R1#sh crypto session
Crypto session current status
Interface: FastEthernet0/0
Session status: UP-ACTIVE
Peer: 200.0.0.1 port 500
IKE SA: local 100.0.0.1/500 remote 200.0.0.1/500 Active
IPSEC FLOW: permit ip host 10.0.0.0 host 10.1.1.0
Active SAs: 2, origin: crypto map
R1#sh crypto isakmp sa
dst src state conn-id slot status
200.0.0.1 100.0.0.1 QM_IDLE 1 0 ACTIVE
Но давайте вернемся к нашим баранам. (1) Мы запустили пинги по туннелю с хоста 10.0.0.0 на адрес 10.1.1.0, (2) маршрутизатор исходя из таблицы маршрутизации должен передать пакет в публичную сеть в исходном виде без каких-либо изменений. (3) Но тут он замечает, что пакет попадает под его собственное правило ACL 101, после чего пакет передается уже протоколу IPSec для дальнейшей работы. (4) Работая по-умолчанию в туннельном режиме IPSec сначала инкапсулирует наш исходны пакет в IPSec PDU, шифрую в соответствии с описанным выше конфигом, а после накидывает поверх новый заголовок IP. При этом его destination address будет IP-адресом соседа по туннелю - 200.0.0.1.
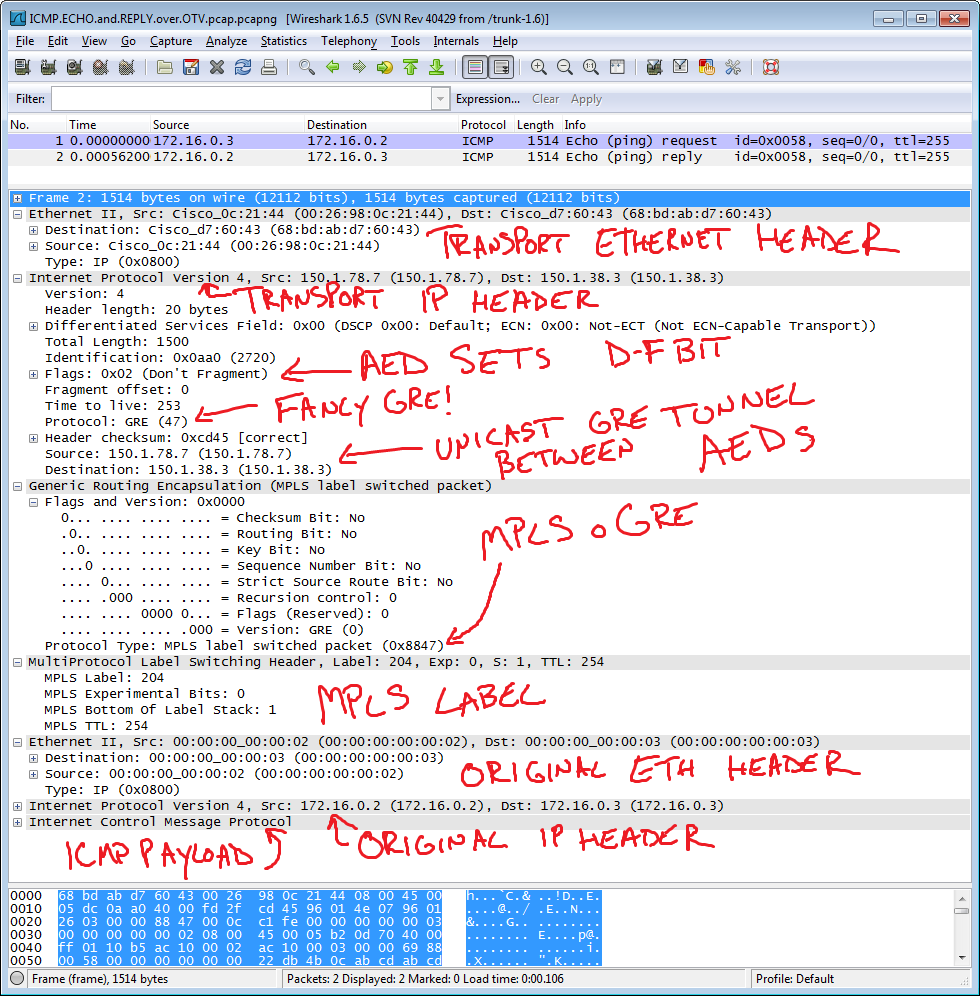
Обратимся к Wireshark, чтобы посмотреть на процесс инкапсуляции:
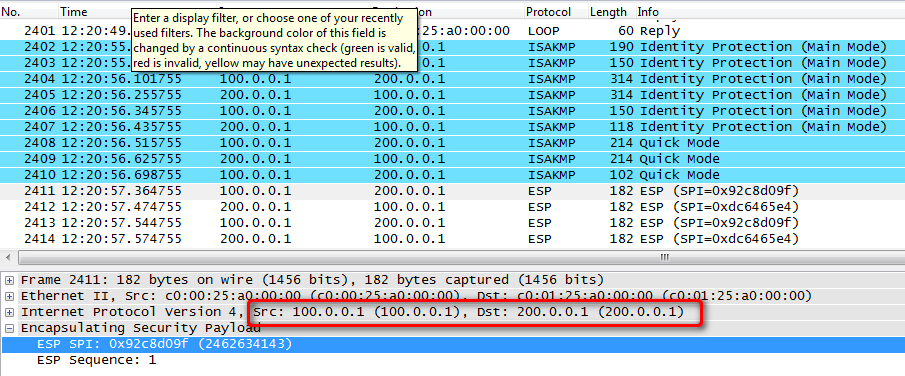
Здесь представлен обмен ICMP-пакетами. Исходные данные зашифрованы вместе со старым IP-заголовком, новый же присвоен исходя из настроек IPSec. (5) Маршрутизатор на конечном узле видит в качестве destination address свой собственный IP, радостно разворачивает его и видит заголовок IPSec, после чего передает его соответствующему протоколу для дальнейшей обработки. IPSec дешифрует его, откидывает ненужную служебную информацию и отправляет полученный пакет в чистом виде дальше.
Наверное, нужно небольшое пояснение. Зачем запускать тот странный пинг с явным указанием адреса отправителя? Всё очень просто, если запустить ping 10.1.1.0, он банально не пройдет, т.к. маршрутизатор услужливо подставит в качестве source address IP физического интерфейса - 100.0.0.1 в нашем случае. Вот только в наших ACL его нет и пакет отправится на шлюз последней надежды.
Вроде все понятно, но... Чувствуются какие-то подводные камни... Точно! Динамическая маршрутизация испортит нам всю малину! Её попросту не получится использовать, ведь всем этим вашим IGP нужен прямой L2-линк между соседями, а наш новый знакомый IPSec по понятным причинам обеспечить это не может. Поэтому в описанной нами конфигурации трафик будет рутиться не таблицей маршрутизации, а на основе ACL и crypto map.
М-м, точно, еще и мультикаст не сможет нормально ходить, ведь в ACL мы задаем только конкретные подсети.
Транспортный режим работы IPSec
Отличий от туннельного тут целый вагон, но самое важное для нас - метод инкапсуляции.
Пакет в туннельном режиме IPSec выглядит так:
А тот же пакет в транспортном так:
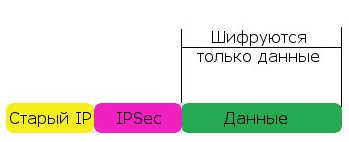
Таким образом, в туннельном режиме пакет шифруется полностью и добавляется только новый IP-заголовок. А в транспортном режиме шифруется только то, что выше сетевого (IP) уровня, остальное же в т.ч. и IP остается без изменений.
Давайте резюмируем. Туннельный режим мы будем использовать для связи приватных сетей через публичную, шифруя при этом данные (тот же GRE, только безопасно). С транспортным же всё несколько иначе, здесь подразумевается, что связность между узлами уже есть, просто нужно шифровать трафик. Где реализовывать такое? Например, в связке клиент-сервер какого-нибудь банковского клиента - сервер то доступен, но данные нуждаются в шифровании.
Только это не про нас, мы хотим объединять сети.
GRE over IPSec
Давайте сразу разберемся в понятиях, не будем путать теплое с мягким - GRE over IPSec и совсем другое IPSec over GRE. Самый распространенный режим работы первый, указанный также в подзаголовке этой статьи. Принцип тут такой, что данные протокола GRE инкапсулируются заголовками ESP или же AH. Схематично это выглядит так:

Обратная же ситуация IPSec over GRE означает, что зашифрованные IPSec-данные будут заворачиваться в GRE/IP, которые в свою очередь не будут подвергаться шифрованию:

Такую схему можно юзать, но при условии, что шифрование всё таки будет происходить, но на отдельном устройстве, перед тем как запулить данные в туннель.

Но это как секс с резиновой женщиной, поэтому самый распространенный метод - это все же GRE over IPSec. Сетевые инженеры за натуралов.
Тем временем вспомним нашу начальную схему и воспроизведем на ней желаемое.

Само собой снова нужно настроить туннельный интерфейс. В плане настройки обыкновенный GRE.
interface Tunnel0
ip address 10.2.2.1 255.255.255.252
tunnel source 100.0.0.1
tunnel destination 200.0.0.1Запиливаем его и рутим туда нужный трафик статическим маршрутом:
ip route 10.1.1.0 255.255.255.255 10.2.2.2В чем будет отличие по настройке IPSec? Да в целом можно ничего не трогать, оно будет работать и так. Но мы же не эникеи какие-нибудь!
Давайте рассуждать. Туннель GRE у нас уже существует, поэтому посредством IPSec его поднимать уже не нужно, а значит этот протокол можно перевести в транспортный режим. Экономия должна быть экономной, по -20 байт с каждого пакета за счет отпиливания ненужного заголовка.
crypto ipsec transform-set AES128-SHA esp-aes esp-sha-hmac
mode transportВажно! Таким образом нужно сконфигурировать обе стороны, иначе никакой дружбы собратья по IPSec водить не будут.
Что дальше? Шифроваться должен весь трафик, который ходит между филиалами, т.е. идущий через туннель. Это значит, что в access list нет нужды прописывать все сети, можно поступить так:
access-list 101 permit gre host 100.0.0.1 host 200.0.0.1Данное условие сработает при прохождении трафика с GRE-заголовком и указанными адресами. Как это выглядит на практике? Давайте разбираться.
1. Пакет с destination address 10.1.1.0 приходит на роутер, который заглядывает в свою таблицу маршрутизации и видит, что отправить его надо на next-hop 10.2.2.2.
R1#sh ip route 10.1.1.0
Routing entry for 10.1.1.0/32
Known via «static», distance 1, metric 0
Routing Descriptor Blocks:
* 10.2.2.2
Route metric is 0, traffic share count is 12. А что там у нас? Туннельный интерфейс с destination address 200.0.0.1. Пакет заворачивается в GRE и новый IP-заголовок.
R1#sh int tun 0
Tunnel0 is up, line protocol is up
Hardware is Tunnel
Internet address is 10.2.2.1/30
MTU 1514 bytes, BW 9 Kbit, DLY 500000 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation TUNNEL, loopback not set
Keepalive not set
Tunnel source 100.0.0.1, destination 200.0.0.1
Tunnel protocol/transport GRE/IP3. А в сеть 200.0.0.1 мы ходим через адрес 100.0.0.2:
R1#sh ip route
Gateway of last resort is 100.0.0.2 to network 0.0.0.0Подсеть же 100.0.0.0/30 висит на интерфейсе Fe0/0:
R1#sh ip route 100.0.0.0
Routing entry for 100.0.0.0/30, 1 known subnets
Attached (1 connections)
C 100.0.0.0 is directly connected, FastEthernet0/0На него в свою очередь применена crupto map с ACL. Трафик подпадает под данные правила (имеется GRE-заголовок и требуемые IP), и всё кроме внешнего заголовка IP шифруется.
Эта схема работы позволяет нормально существовать протоколам динамической маршрутизации и ходить мультикаст-трафику, оставляя при этом возможность шифрования. Враг не пройдет.
Замечание. Вообще-то можно выкинуть заголовок GRE из пакетов, указав на обоих концах туннеля режим работы IPIP:
interface Tunnel0
tunnel mode ipipЕдинственный минус при этом, что инкапсулировать тогда будет возможно только данные IP, а не любые как в случае с протоколом GRE.
IPSec VTI
Ну, а это уже рекомендованный самой циской тип Site-to-Site VPN с использованием IPSec - Virtual Tunnel Interface или просто VTI. Давайте попробуем разобраться в разнице настройки. Нам уже не нужно создавать crypto-map, а вместе с ней ACL, требуется только запилить IPSec-профиль:
crypto isakmp policy 1
authentication pre-share
crypto isakmp key CISCO address 100.0.0.1
!
!
crypto ipsec transform-set AES128-SHA esp-aes esp-sha-hmac
mode transport
crypto ipsec profile VTI-P
set transform-set AES128-SHA
И уже созданный профиль привязываем к туннельному интерфейсу:
interface Tunnel0
tunnel protection ipsec profile VTI-PПочему такое отличие по сравнению с создававшимися ранее crypto-map? Нам уже не нужны ACL, т.к. весь трафик идущий в туннель шифруется. При этом указанные карты шифрования таки создаются, но не пользователем, а в автоматическом режиме.
Мы получили самый обычный Tunnel Protection, но без VTI. Распространен он очень сильно. А уже добавив команду tunnel mode ipsec ipv4 мы получим этот самый VTI. В чем отличие от обычного GRE? По сути только в процессе инкапсуляции, т.к. в VTI просто нет четырехбайтового GRE-заголовка.
Подробнее на английском.
DMVPN
Настройка DMVPN на маршрутизаторах Cisco. XGU.RU
dmvpn/config XGU.RU
В качестве изюминки на кексе рассмотрим Dymamic Multipoint VPN или же просто DMVPN. До этого мы говорили об универсальных механизмах создания туннелей, а вот этот зверь уже проприетарная разработка Cisco со всеми вытекающими.
Проблемы с безопасностью мы порешали путем шифрования данных, и с IGP тоже, ведь с GRE over IPSec мы можем юзать протоколы динамической маршрутизации. Теперь разберемся с масштабируемостью нашей сети.
Ладно, если у нас такая маленькая сетка:
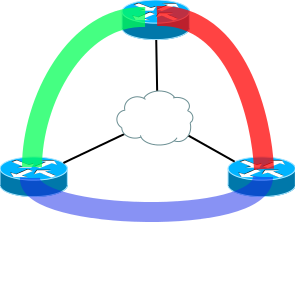
Всего по два туннеля на каждом из узлов. Попробуем добавить еще один узел:
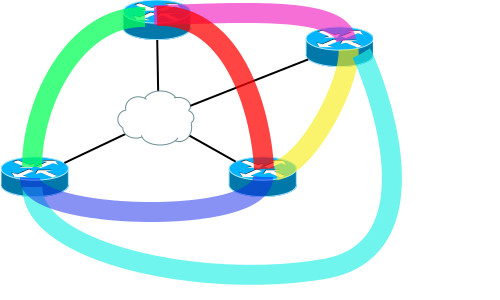
А потом еще один...
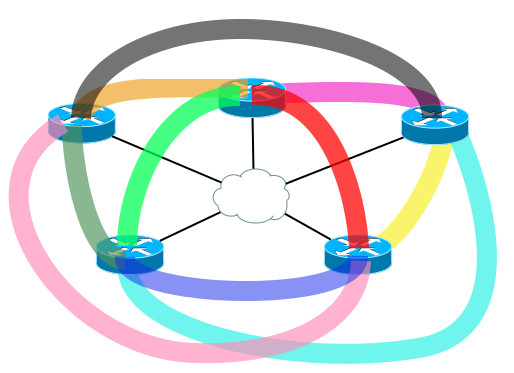
Туннелей нужно всё больше и больше, чтобы топология была адекватно связана. Проблемка со сложностью вида m*(m-1)/2.
Окей, давайте не будем использовать Full-Mesh, а организуем топологию Hub-and-Spoke только с одной центральной точкой. Но тогда весь трафик со всех филиалов будет проходить через центральный узел.
В нашем случае DMVPN станет панацеей от всех этих проблем. Как это работает? Выбирается одна или несколько точек, которые назначаются центральными (Hub). Хаб является сервером, к которому будут подключаться клиенты (Spoke) и получать всю необходимую им информацию. При этом имеются все возможные удобства:
> Шифрование данных посредством IPSec.
> Возможность передачи данных клиент-клиент минуя центральный узел.
> Только на центральном Hub-узле требуется публичный IP-адрес. Клиенты при этом могут иметь динамические IP или вообще сидеть за NAT'ом с приватными адресами (курим технологию NAT traversal). Правда есть косяк с созданием динамических туннелей, но это уже другая история.
Теория и практика DMVPN
Давайте пока что отвлечемся от нашей разветвленной сети и будем рассматривать в качестве примера узел в Москве, доступ в интернет через некоего провайдера, а также филиалы в Новосибе, Томске и заграницей в Брно.
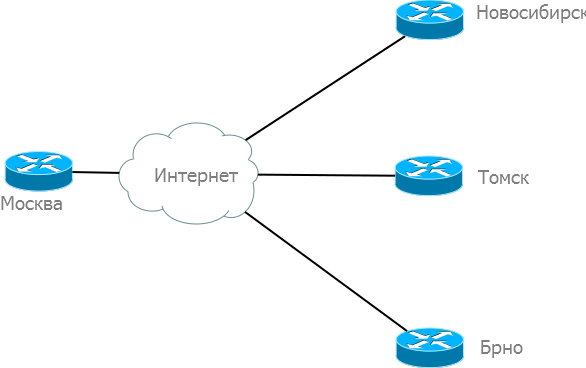
Взглянем на новый IP-план с подсетями для наших филиалов:
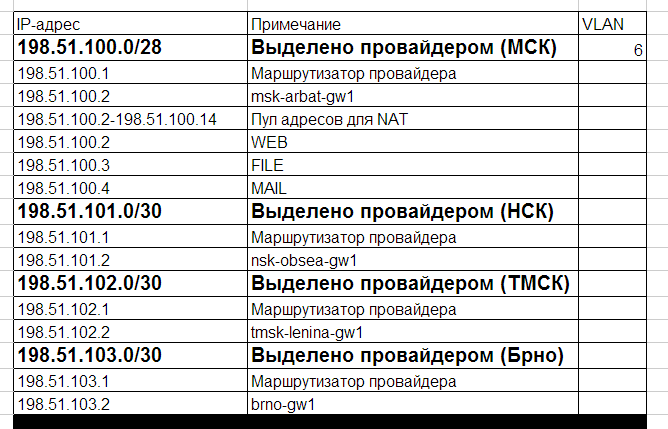
LAN:

Внутренняя сетка для туннельных интерфейсов:
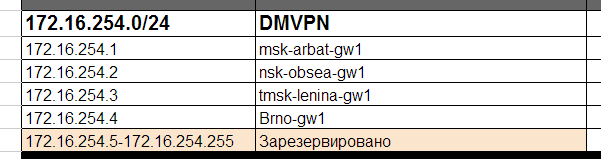
А также Loopback-адреса для них:
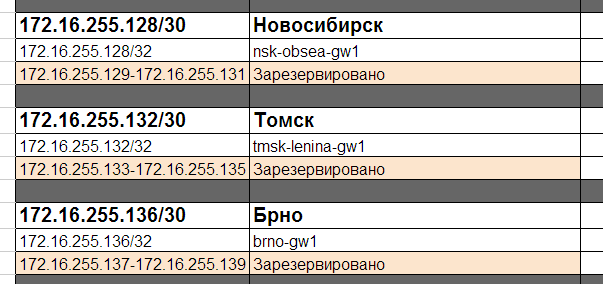
Мы хотим, чтобы один-единственный динамически туннель присутствовал только на центральном узле. Его мы настроим в самом начале, а дальше при добавлении новых удаленных клиентов здесь уже не потребуются никакие изменения. Легкость масштабирования в чистом виде. Не потребуются новые туннельные интерфейсы и существующий тоже не придется перенастраивать.
То есть при добавлении нового узла в нашу сеть только его и нужно будет настраивать.
Поднимаем везде протокол NHRP - NBMA Next Hop resolution Protocol.
Требуется он для динамического изучения адресов новых удаленных точек, желающих подключиться к хабу. Благодаря этой технологии multipoint VPN и живет. Здесь хаб, читай - центральный узел, играет роль NHS – Next-Hop Server, а все удаленные узлы будут клиентами или NHC – Next-Hop Client. Без наглядного примера разобраться сложно, поэтому давайте сразу к делу.
Настроим хаб:
interface Tunnel0
ip address 172.16.254.1 255.255.255.0
ip nhrp map multicast dynamic
ip nhrp network-id 1
tunnel source FastEthernet0/1.6
tunnel mode gre multipoint
Давайте разбираться, что же мы сейчас настроили.
ip address 172.16.254.1 255.255.255.0 - это айпишник из нужного нам диапазона.
ip nhrp map multicast dynamic - то самое динамическое изучение NHRP-данных от клиентов. Понятное дело, если клиентов у нас валом и они вдобавок имеют динамические IP-адреса, то явного соответствия внешних айпишников внутренним задать не получится.
ip nhrp network-id 1 - назначаем Network ID, некий идентификатор, который в принципе не обязательно должен быть одинаковым у всех узлов сети. Тут он напоминает Router-ID у протокола OSPF.
tunnel source FastEthernet0/1.6 - скажем так, рудимент протокола GRE, привязка к физическому интерфейсу (или сабинтерфейсу, если брать наш случай).
tunnel mode gre multipoint - включаем терминирование всех туннелей от Spoke-точек. Будет он, следуя оригинальному термину, Point-to-MultiPoint, точка-многоточка.
Теперь конфигурируем филиалы:
interface Tunnel0
ip address 172.16.254.2 255.255.255.0
ip nhrp map 172.16.254.1 198.51.100.2
ip nhrp map multicast 198.51.100.2
ip nhrp network-id 1
ip nhrp nhs 172.16.254.1
ip nhrp registration no-unique
tunnel source FastEthernet0/0
tunnel mode gre multipoint
И сразу рассмотрим проделанное.
ip address 172.16.254.2 255.255.255.0 - опять таки IP из нужного диапазона.
ip nhrp map 172.16.254.1 198.51.100.2 - настраиваем статическое соответствие внутреннего и внешнего адресов нашего хаба.
ip nhrp map multicast 198.51.100.2 - теперь на хаб будет идти весь мультикастовый трафик.
Цитата: Туннель и мульткаст
Если не настроить правило для мультикастового трафика, то вы обречены на некоторые проблемы. Вот, например, с OSPF. Настроили мы его, поднялся пиринг, все узлы перешли в состояние Full, дружно обмениваются маршрутами... И тут, бац! Пиринг обрушивается, пинги пропадают, истек dead-timer:
*Mar 1 01:51:20.331: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.2 on Tunnel0 from FULL to DOWN, Neighbor Down: Dead timer expired
msk-arbat-gw1#
*Mar 1 01:51:25.435: %OSPF-5-ADJCHG: Process 1, Nbr 172.16.255.2 on Tunnel0 from LOADING to FULL, Loading DoneДавайте подебажим проблему, поглядим логи:
*Mar 1 01:53:44.915: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.4 from 172.16.2.1
*Mar 1 01:53:44.919: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.7 from 172.16.2.33
*Mar 1 01:53:44.923: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.5 from 172.16.2.17
*Mar 1 01:53:44.923: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.8 from 172.16.2.129
*Mar 1 01:53:44.963: OSPF: Send hello to 224.0.0.5 area 0 on Tunnel0 from 172.16.254.1
msk-arbat-gw1#
*Mar 1 01:53:54.919: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.4 from 172.16.2.1
*Mar 1 01:53:54.923: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.7 from 172.16.2.33
*Mar 1 01:53:54.927: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.5 from 172.16.2.17
*Mar 1 01:53:54.931: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.8 from 172.16.2.129
*Mar 1 01:53:54.963: OSPF: Send hello to 224.0.0.5 area 0 on Tunnel0 from 172.16.254.1
msk-arbat-gw1#
*Mar 1 01:54:04.919: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.4 from 172.16.2.1
*Mar 1 01:54:04.927: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.7 from 172.16.2.33
*Mar 1 01:54:04.931: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.5 from 172.16.2.17
*Mar 1 01:54:04.935: OSPF: Send hello to 224.0.0.5 area 0 on FastEthernet0/1.8 from 172.16.2.129
*Mar 1 01:54:04.963: OSPF: Send hello to 224.0.0.5 area 0 on Tunnel0 from 172.16.254.1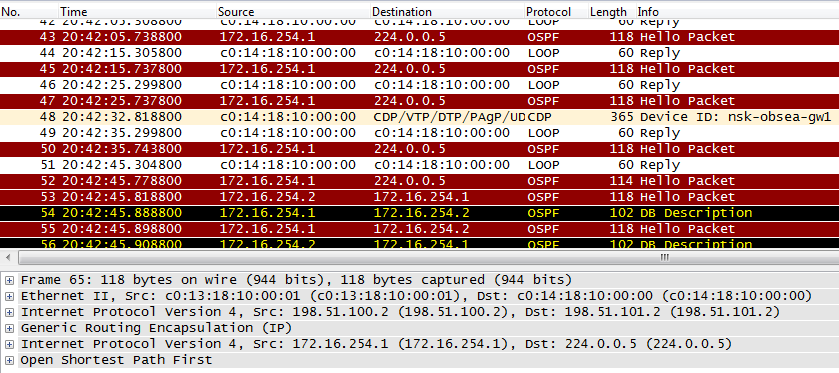
А видим, что хаб послал аж пять Hello-пакетов и всего лишь один получил от филиала. В чем дело? Просто-напросто маршрутизатор не понимает, куда запуливать мультикастовые сообщения с destination address 224.0.0.5. В итоге хаб эти сообщения не получает и обрывает OSPF-сессию.
Продолжим разбираться с настройкой клиента.
ip nhrp network-id 1 - все тот же Network ID, да-да, и он может не совпадать с этим значением на хабе.
ip nhrp nhs 172.16.254.1 - адрес NHRP-сервера, т.е. статически прописанный адрес хаба. Вот почему для центрального узла нам нужен неизменный публичный IP. Именно на 172.16.254.1 клиенты будут отправлять запросы на регистрацию. В запросе содержится настроенный локальный адрес туннельного интерфейса и публичный адрес клиента (да-да, про нахождение клиента за NAT'ом пока не будем говорить). Всю полученную информацию хаб любовно записывает в свою NHRP-таблицу, в которой отражено соответствие IP-адресов. Да, эту самую таблицу он раздает по запросу клиентских Spoke-маршутизаторов.
ip nhrp registration no-unique - обязательная команда в случае выдачи клиентам динамических адресов.
tunnel source FastEthernet0/0 - биндим туннель на физический интерфейс.
tunnel mode gre multipoint - задаем тип туннеля mGRE, теперь возможно поднимать динамические туннели не только до хаба, но и до других клиентов.
Сейчас ни один из клиентов у нас не находится за NAT'ом, поэтому можно проверить, что мы имеем:
msk-arbat-gw1#sh int tun 0
Tunnel0 is up, line protocol is up
Hardware is Tunnel
Internet address is 172.16.254.1/24
MTU 1514 bytes, BW 9 Kbit, DLY 500000 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation TUNNEL, loopback not set
Keepalive not set
Tunnel source 198.51.100.2 (FastEthernet0/1.6), destination UNKNOWN
Tunnel protocol/transport multi-GRE/IP
Key disabled, sequencing disabled
Checksumming of packets disabledmsk-arbat-gw1#ping 172.16.254.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.254.2, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 176/213/284 msmsk-arbat-gw1#sh ip nhrp brief
Target Via NBMA Mode Intfc Claimed
172.16.254.2/32 172.16.254.2 198.51.101.2 dynamic Tu0 < >
msk-arbat-gw1#sh ip nhrp
172.16.254.2/32 via 172.16.254.2, Tunnel0 created 00:09:48, expire 01:50:11
Type: dynamic, Flags: authoritative unique registered
NBMA address: 198.51.101.2
nsk-obsea-gw1#sh ip nhrp brief
Target Via NBMA Mode Intfc Claimed
172.16.254.1/32 172.16.254.1 198.51.100.2 static Tu0 < >Видим, что Tunnel0 is up, line protocol is up, и он имеет следующие параметры: Tunnel source 198.51.100.2 (FastEthernet0/1.6), destination UNKNOWN
Tunnel protocol/transport multi-GRE/IP
Отлично!
OSPF
Связать мы всё связали, но ничего не взлетит, пока не настроена маршрутизация. У каждого протокола при этом будут свои тонкости, но мы для примера возьмем полюбившийся уже OSPF.
У нас с вами широковещательная сеть L2 на основе туннелей, поэтому на них нужно указать тип сети Broadcast на всех туннельных интерфейсах всех узлов без исключения:
ip ospf network broadcastОпять таки в этой сети будет выбираться DR и по вполне понятным причинам им должен быть именно хаб. Давайте запретим всем Spoke-маршрутизаторам участие в выборах DR (как сложно не пошутить про самые демократические выборы, хе-хе):
ip ospf priority 0Также определим сети, которые будут анонсироваться:
router ospf 1
network 172.16.0.0 0.0.255.255 area 0Проверяем, что всё анонсируется:
msk-arbat-gw1#sh ip route
Gateway of last resort is 198.51.100.1 to network 0.0.0.0
172.16.0.0/16 is variably subnetted, 7 subnets, 3 masks
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
C 172.16.255.1/32 is directly connected, Loopback0
C 172.16.254.0/24 is directly connected, Tunnel0
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
O 172.16.255.128/32 [110/11112] via 172.16.254.2, 00:05:14, Tunnel0
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 [1/0] via 198.51.100.1И что пинги ходят:
msk-arbat-gw1#ping 172.16.255.128
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.255.128, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 60/70/80 msСнимем вайршарком дамп с маршрутизатора nsk-obsea-gw1 fa0/0 и поглядим на уходящие в интернеты пакетики:
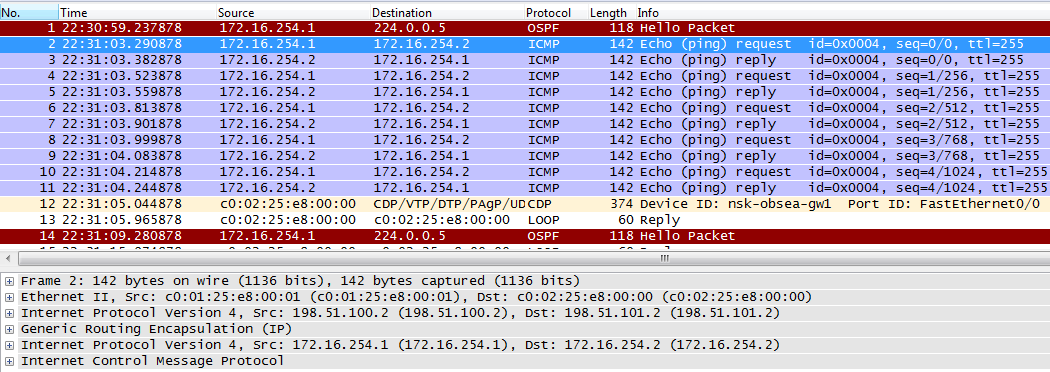
Запустим пинги между филиалами:
nsk-obsea-gw1#ping 172.16.255.132
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.255.132, timeout is 2 seconds:
!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 132/231/492 ms
nsk-obsea-gw1#traceroute 172.16.255.132
Type escape sequence to abort.
Tracing the route to 172.16.255.132
1 172.16.254.3 240 msec * 172 msec
nsk-obsea-gw1#sh ip nhrp br
Target Via NBMA Mode Intfc Claimed
172.16.254.1/32 172.16.254.1 198.51.100.2 static Tu0 < >
172.16.254.3/32 172.16.254.3 198.51.102.2 dynamic Tu0 < >Отлично, пакеты не проходят через хаб, а прямиком через глобальную сеть идут к целевому Spoke-узлу. Но это на вид всё так просто.
Как выглядит механика этого процесса?
1. Отправляются пинги на Loopback-адрес маршрутизатора в Томске.
2. Проверяется таблица маршрутизации, исходя из которой следующим хопом будет:
nsk-obsea-gw1#sh ip route 172.16.255.132
Routing entry for 172.16.255.132/32
Known via «ospf 1», distance 110, metric 11112, type intra area
Last update from 172.16.254.3 on Tunnel0, 00:18:47 ago
Routing Descriptor Blocks:
* 172.16.254.3, from 172.16.255.132, 00:18:47 ago, via Tunnel0
Route metric is 11112, traffic share count is 1* 172.16.254.3, from 172.16.255.132, 00:18:47 ago, via Tunnel0 - адрес сети directly connected к нашему Tunnel 0.
nsk-obsea-gw1#sh ip route 172.16.254.3
Routing entry for 172.16.254.0/24
Known via «connected», distance 0, metric 0 (connected, via interface)
Routing Descriptor Blocks:
* directly connected, via Tunnel0
Route metric is 0, traffic share count is 1* directly connected, via Tunnel0 - и верно.
3. Интерфейсы сконфигурированы на использование NHRP. Поглядим на таблицу соответствия, которую анонсирует хаб:
nsk-obsea-gw1#sh ip nhrp brief
Target Via NBMA Mode Intfc Claimed
172.16.254.1/32 172.16.254.1 198.51.100.2 static Tu0 < >Интересно. Адрес 172.16.254.3 для NHRP неизвестен и потому пакет уходит на хаб с публичным IP 198.51.100.2.
msk-arbat-gw1, fa0/1 - вот он:
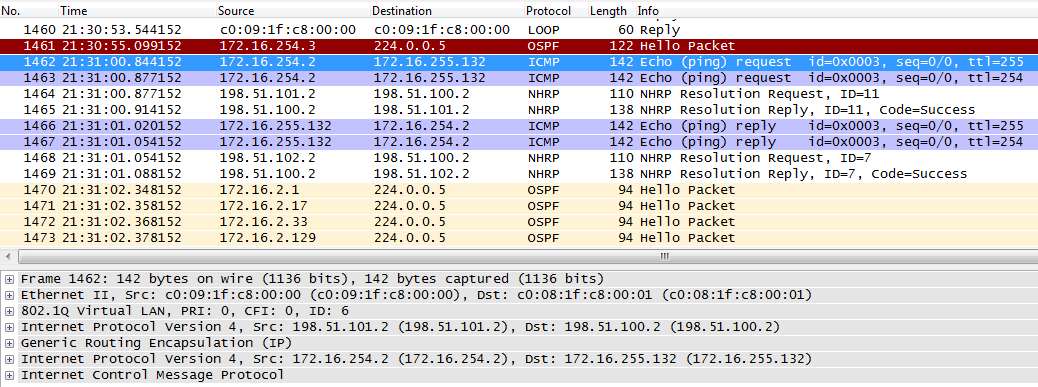
Хаб быстро смекает в чем дело, и заруливает пакеты куда надо.
msk-arbat-gw1, fa0/1:
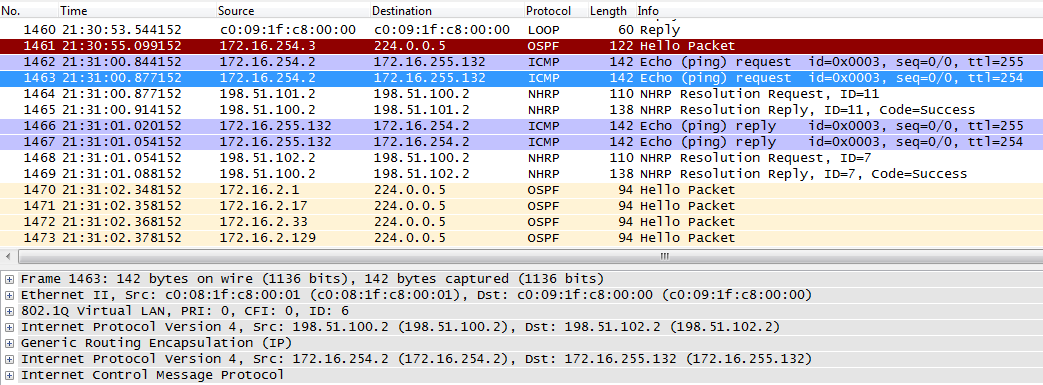
4. Тем временем маршрутизатор в филиале Новосибирска отсылает NHRP-запрос, пытаясь разузнать про адрес 172.16.254.3.
msk-arbat-gw1, fa0/1:
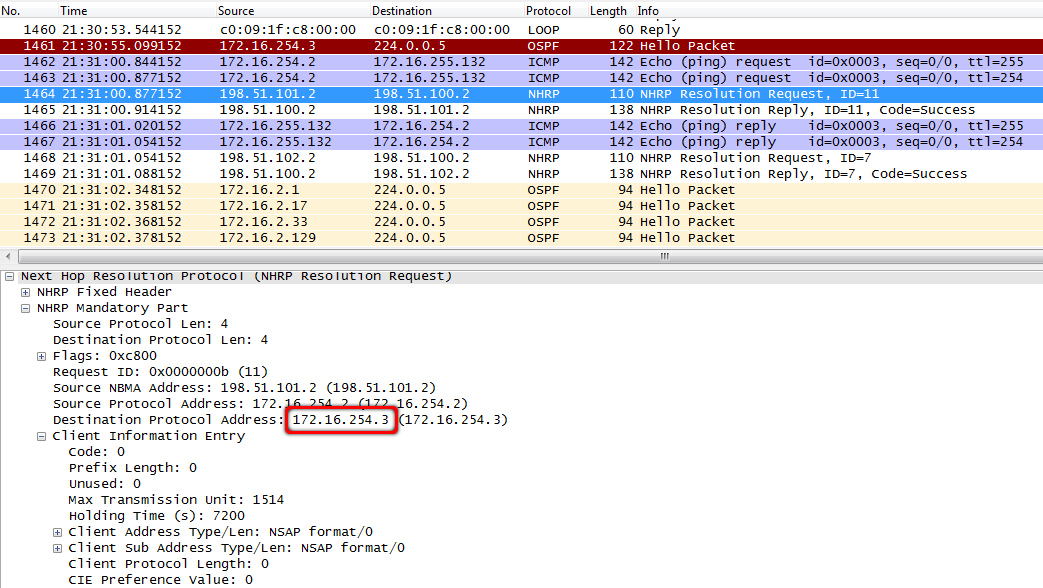
5. И хаб может на этот вопрос ответить.
msk-arbat-gw1#sh ip nhr br
Target Via NBMA Mode Intfc Claimed
172.16.254.2/32 172.16.254.2 198.51.101.2 dynamic Tu0 < >
172.16.254.3/32 172.16.254.3 198.51.102.2 dynamic Tu0 < >Ценная информация уходит обратно в NHRP-ответе.
msk-arbat-gw1, fa0/1:
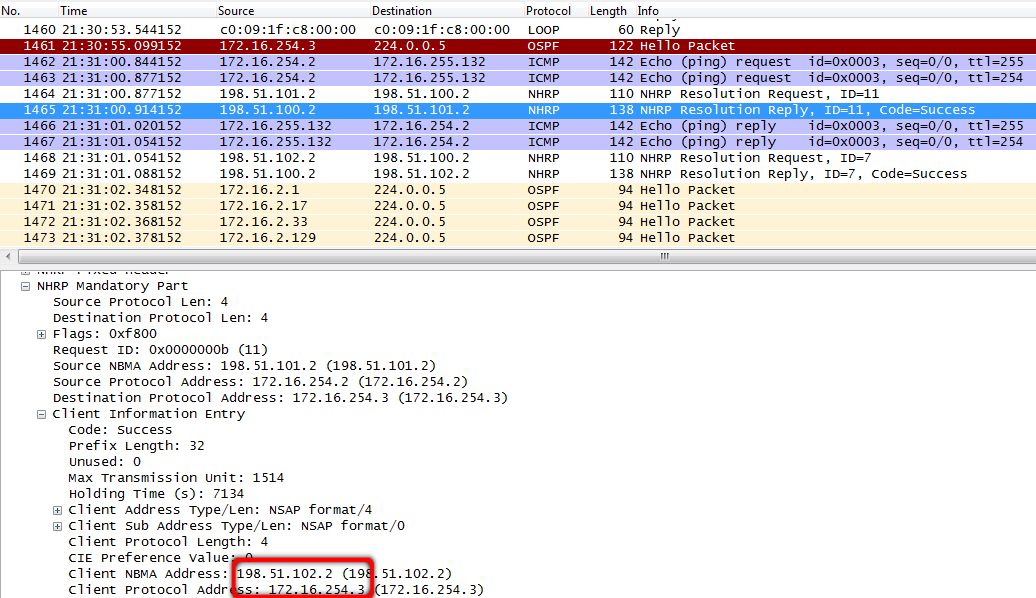
На этом роль хаба в общении двух Spoke-маршрутизаторов завершена.
6. Вот ICMP-запрос пришел на маршрутизатор в Томске.
tmsk-lenina-gw1, fa0/0:
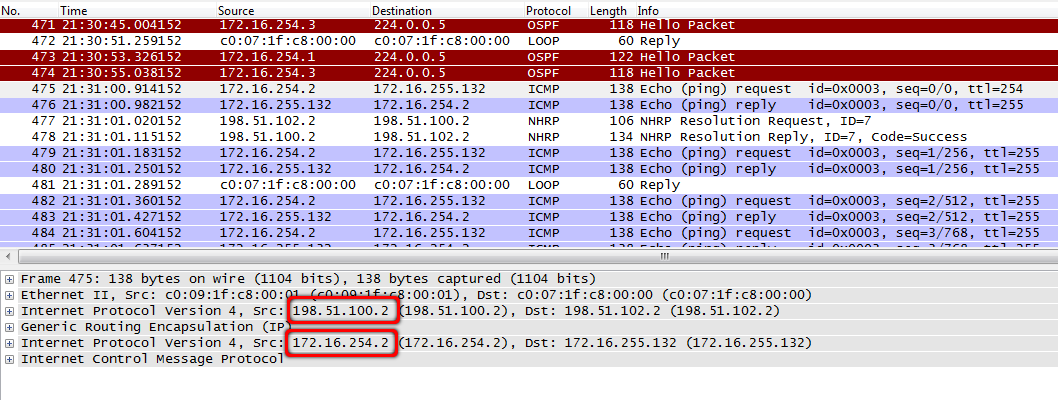
Да, видно, что внешний заголовок гласит, что source address - это адрес хаба, но внутри присутствует заголовок с изначальным IP Новосибирского маршрутизатора.
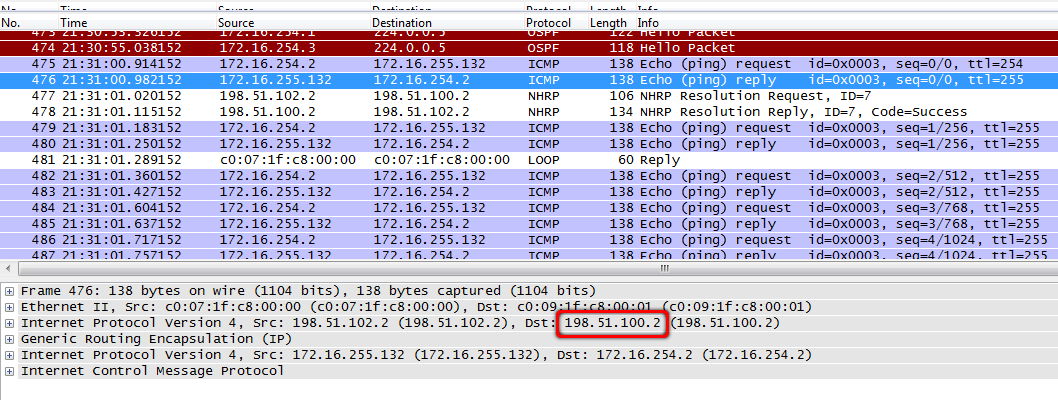
7. Томск тоже пока не в курсе, кто там за IP 172.16.254.2 отправил ICMP-запрос.
tmsk-lenina-gw1(config-if)#do sh ip nh br
Target Via NBMA Mode Intfc Claimed
172.16.254.1/32 172.16.254.1 198.51.100.2 static Tu0 < >И ICMP-ответ уходит не к непосредственному адресату, на хаб.
tmsk-lenina-gw1, fa0/0:
8. Дальше следует закономерный вопрос о публичном адресе отправителя.
tmsk-lenina-gw1, fa0/0:
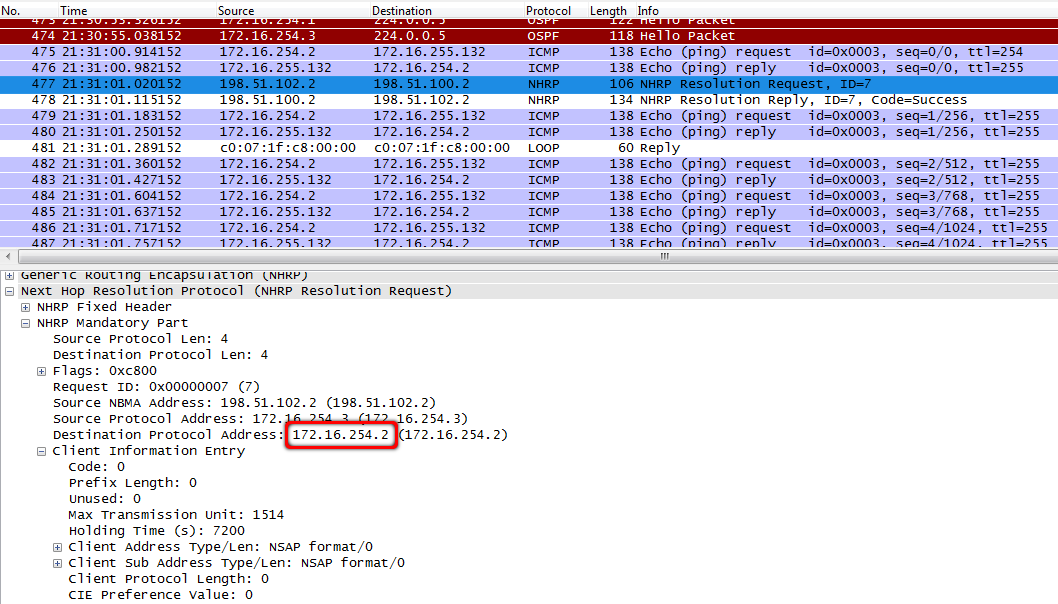
9. За этим следует ответ от хаба.
tmsk-lenina-gw1, fa0/0:
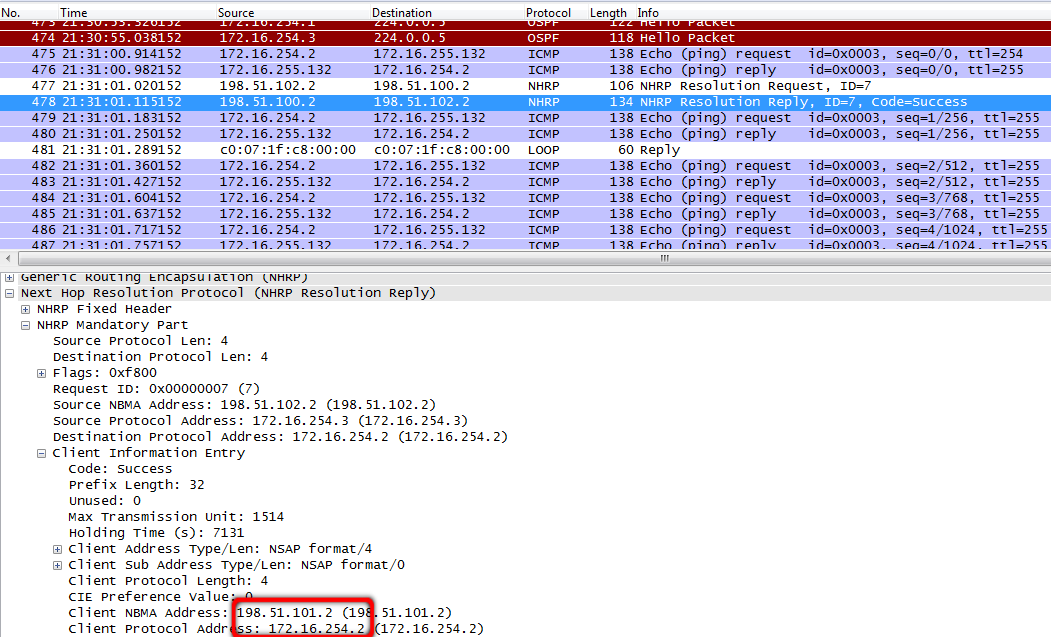
10. В итоге все узлы становятся обладателями актуальной NHRP-информации:
msk-arbat-gw1(config-if)#do sh ip nhr br
Target Via NBMA Mode Intfc Claimed
172.16.254.2/32 172.16.254.2 198.51.101.2 dynamic Tu0 < >
172.16.254.3/32 172.16.254.3 198.51.102.2 dynamic Tu0 < >
nsk-obsea-gw1(config-if)#do sh ip nhr br
Target Via NBMA Mode Intfc Claimed
172.16.254.1/32 172.16.254.1 198.51.100.2 static Tu0 < >
172.16.254.3/32 172.16.254.3 198.51.102.2 dynamic Tu0 < >
tmsk-lenina-gw1(config-if)#do sh ip nh br
Target Via NBMA Mode Intfc Claimed
172.16.254.1/32 172.16.254.1 198.51.100.2 static Tu0 < >
172.16.254.2/32 172.16.254.2 198.51.101.2 dynamic Tu0 < >То есть информация не рассылается хабом автоматически, а происходит это только по запросу клиентов, ведь только они знают куда им для этого обращаться. Хаб при этом о клиентах сначала ничего не знает.
11. Новый ICMP-запрос уйдет уже по другому:
nsk-obsea-gw1#sh ip route 172.16.255.132
Routing entry for 172.16.255.132/32
Known via «ospf 1», distance 110, metric 11112, type intra area
Last update from 172.16.254.3 on Tunnel0, 00:20:24 ago
Routing Descriptor Blocks:
* 172.16.254.3, from 172.16.255.132, 00:20:24 ago, via Tunnel0
Route metric is 11112, traffic share count is 1Подсеть 172.16.254.0 у нас подключена к туннельному интерфейсу Tunnel 0.
nsk-obsea-gw1#sh ip route 172.16.254.3
Routing entry for 172.16.254.0/24
Known via «connected», distance 0, metric 0 (connected, via interface)
Routing Descriptor Blocks:
* directly connected, via Tunnel0
Route metric is 0, traffic share count is 112. И еще разок. Tunnel 0 - это mGRE, а в исходя из таблички NHRP весь трафик с next hop 172.16.254.3 инкапсулируется в GRE с внешним IP-заголовком destination address 198.51.102.2 (при этом в роли source address выступит адрес физического интерфейса 198.51.101.2):
nsk-obsea-gw1(config-if)#do sh ip nhr br
Target Via NBMA Mode Intfc Claimed
172.16.254.1/32 172.16.254.1 198.51.100.2 static Tu0 < >
172.16.254.3/32 172.16.254.3 198.51.102.2 dynamic Tu0 < >tmsk-lenina-gw1, fa0/0:
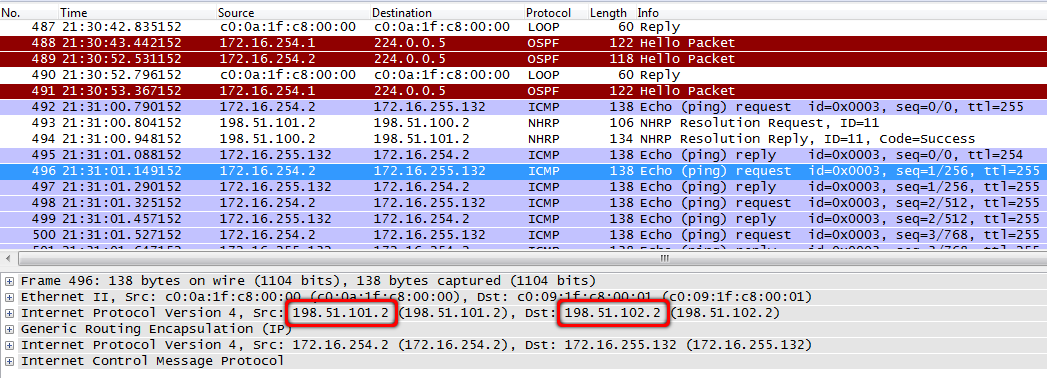
13. Теперь пакет с destiantion address 198.51.102.2 уходит следуя таблице маршрутизации:
Gateway of last resort is 198.51.101.1 to network 0.0.0.0В этом месте требуется небольшое уточнение. Да, филиалы общаются друг с другом не гоняя трафик через центральный узел, но без хаба ничего функционировать не будет, ведь именно он анонсирует клиентам NHRP-таблицу и все требующиеся маршруты. Филиалы по факту распространяют информацию о маршрутах не напрямую друг другу, а через хаб.
Сейчас конфиг узлов такой:
Резюмируя. С чем мы уже разобрались:
- Филиалы подключены друг к другу, связность настроена.
- Поднята маршрутизация. Через mGRE без проблем гуляют IGP.
- Легкость масштабирования сети. При появлении нового Spoke-узла настроить нужно только его, остальных узлов сети и хаба это не касается.
- Сняли нагрузку с хаба. Он теперь гоняет только служебный трафик.
Что теперь? Б - безопасность.
IPSec
Эту нашу проблему решит шифрование. Да, при Site-to-Site VPN еще можно юзать pre-shared key, ведь IP-адрес у IPSec-пира задавался жестко, но с DMVPN такой фокус не пройдет - здесь нам нужна адаптивность конфигурации, мы ведь даже адресов нейборов не знаем наперед. Поэтому мы будем использовать сертификаты, в контексте цисок статью об этом можно покурить на xgu.
Это для следующих частей, а пока попользуем самый обыкновенный pre-shared key:
crypto isakmp policy 1
authentication pre-shareРанее мы обсуждали Tunnel Protection и VTI, но здесь всё иначе, например, мы зададим шаблонный адрес:
crypto isakmp key DMVPNpass address 0.0.0.0 0.0.0.0Круто да? Только тут кроется и дырка, ведь IPSec-сессию с нашим хабом может поднять абсолютно любой хост, достаточно знать ключ.
Использовать мы будем транспортный режим:
crypto ipsec transform-set AES128-SHA esp-aes esp-sha-hmac
mode transport
crypto ipsec profile DMVPN-P
set transform-set AES128-SHAПрофиль мы создали, теперь применим его на интерфейс туннеля:
interface Tunnel0
tunnel protection ipsec profile DMVPN-P
Проверим результат, задампив трафик с msk-arbat-gw1, fa0/1:
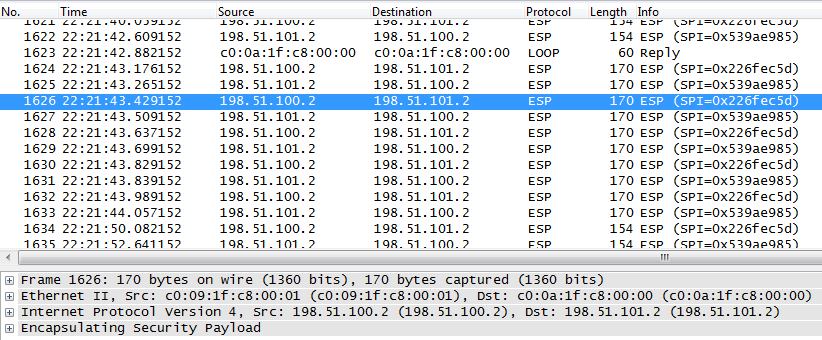
Ни в коем случае не ставьте режим tunnel mode ipsec ipv4
В нашем случае туннели IPSec и crypto-map будут динамически подниматься при каждом сеансе между филиалами, но вот для каналов Hub-Spoke они всегда будут неизменны.
NAT-Traversal
Не пугайтесь, под занавес статьи не будет обсуждения принципов работы NAT traversal (aka NAT-T), всё будет коротко и по делу. Что это и с чем едят. Благодаря наличию дополнительного заголовка UDP протокол IPSec способен поднимать туннели сквозь NAT. Таким образом даже лишенный публичного адреса узел способен запустить VPN-сессию. Вся прелесть в том, что данный функционал уже не нужно включать/настраивать, он уже работает по дефолту.
Тем временем подкинем самим себе проблем и добавим в Брно еще один маршрутизатор.
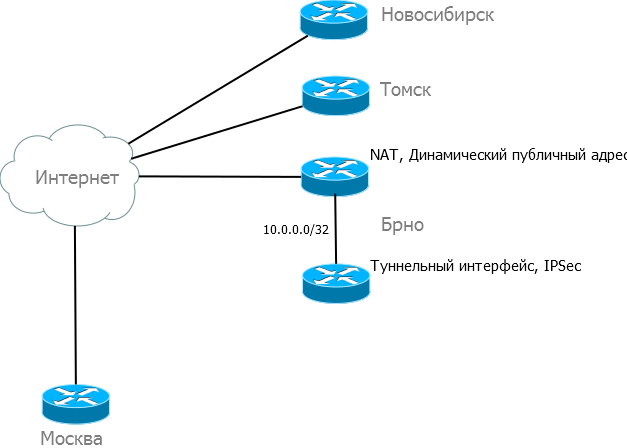
Пусть это будет маршрутизатор местного прова, вся задача которого натить нашу сетку. Т.е. на физическом интерфейсе роутера в филиале будет динамический IP из приватного пула. Сам по себе протокол GRE тут будет сосать лапу, VPN при таком раскладе не поднять. Опять таки IPSec это может, но мы замучаемся ставить костыли. А вот если добавить к нему на помощь mGRE!..
Взглянем на NHRP-таблицу из нашего примера:
msk-arbat-gw1#show ip nhrp brief
Target Via NBMA Mode Intfc Claimed
172.16.254.4/32 172.16.254.4 10.0.0.2 dynamic Tu0 < >10.0.0.2 - как видим, перед нами именно приватный IP от прова.
При этом в route table обязан иметься маршрут до этого выданного провайдером адреса. Так или иначе, пусть даже это маршрут по-умолчанию.
На туннельном интерфейса мы развернули IPSec, а значит там должны иметься crypto-map:
msk-arbat-gw1#show crypto map
Crypto Map «Tunnel0-head-0» 65537 ipsec-isakmp
Map is a PROFILE INSTANCE.
Peer = 198.51.103.2
Extended IP access list
access-list permit gre host 198.51.100.2 host 10.0.0.2
Current peer: 198.51.103.2
Security association lifetime: 4608000 kilobytes/3600 seconds
PFS (Y/N): N
Transform sets={
AES128-SHA,
}
Interfaces using crypto map Tunnel0-head-0:
Tunnel0Peer = 198.51.103.2
Current peer: 198.51.103.2
Получается, что туннель у нас поднимается между 198.51.100.2 и 198.51.103.2, а уже потом шифрованный посредством NAT-T данные в туннеле идут на приватный 10.0.0.2
Остальное вам уже известно.
На хабре имеется крутой ликбез по NHRP.

